

百度最近开源了一个叫Unlimited OCR的模型,刚上线5天,GitHub Star就破万了。在AI开源项目里,这个速度相当惊人。
更关键的是,它解决了一个很实在的问题:长文档解析。
OCR不新鲜,但长文档OCR很头疼
OCR(光学字符识别)技术已经存在很多年了。你把一张照片里的文字提取出来,现在的技术基本都能做到。但问题是,现实场景中的文档往往很长——一本电子书、一份几十页的合同、一篇长篇论文……这些文档如果一页一页处理,效率低得可怕。
传统的OCR模型,通常有输入长度限制。比如一次只能处理几千个token,超过这个长度就得切分,切完再拼接。这个过程不仅麻烦,还容易出错——上下文断了,理解就偏了。
Unlimited OCR想解决的,就是这个痛点。
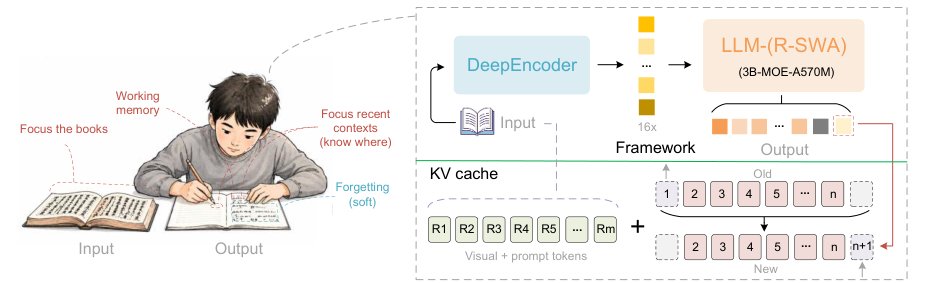
核心技术:Reference Sliding Window Attention
百度团队给Unlimited OCR设计了一个创新的注意力机制,名字叫Reference Sliding Window Attention(参考滑动窗口注意力)。
这个名字听起来很学术,但核心思路其实不难理解:
传统的注意力机制,模型要”看”所有输入的内容,计算量随长度平方增长。所以输入一长,模型就撑不住了。百度的新方法是,让模型在处理长文档时,有一个”参考窗口”,只重点关注当前段落和关键的参考信息,而不是从头到尾通读一遍。
打个比方,就像你读一本厚书,不会每翻一页都把前面所有内容重新回忆一遍。你会记住关键信息,然后带着这些关键信息继续读。Unlimited OCR做的,就是让AI也学会这种”带着重点读”的能力。
成绩怎么样?相当亮眼
在OmniDocBench v1.6这个权威的文档理解基准测试上,Unlimited OCR拿到了93.92%的分数。
这个分数是什么概念?在文档解析这个领域,90%以上就已经是顶尖水平了。93.92%说明它不仅能识别文字,还能很好地理解文档的结构——标题、段落、表格、列表,这些元素之间的关系都能准确把握。
更实用的是速度。相比DeepSeek的OCR方案,Unlimited OCR的推理速度提升了12.7%。而且文档越长,这个优势越明显。这对于需要批量处理文档的企业来说,意味着实实在在的成本节省。
3B参数,小而精
值得注意的是,Unlimited OCR只有30亿参数。
在动辄百亿、千亿参数的大模型时代,30亿听起来很小。但OCR这个任务,不需要模型懂诗词歌赋、不需要它会写代码,它只需要准确地看懂文档。30亿参数,对于这个特定任务来说,已经足够了。
小模型的好处很明显:跑得快、吃得少、部署方便。普通的服务器就能跑,不需要昂贵的GPU集群。这对于中小企业来说,门槛低了很多。
应用场景很广泛
Unlimited OCR能做的事,远不止”把图片转成文字”这么简单。
文档数字化是最直接的。企业里堆积如山的纸质档案、扫描件,以前要人工录入或者买昂贵的OCR软件,现在用一个开源模型就能批量处理。
大模型的长程记忆是另一个重要方向。现在的大模型,上下文长度虽然越来越长,但处理超长文档时还是会”失忆”。Unlimited OCR的高效解析能力,可以作为前置处理模块,帮大模型更好地消化长内容。
还有法律、金融、医疗这些行业,每天都要处理大量长文档。合同审查、财报分析、病历整理……如果AI能先把文档结构理清楚,后续的分析工作会高效很多。
写在最后
Unlimited OCR的火爆,说明了一件事:解决真实问题的AI,永远有市场。
它不是最 flashy 的模型,不会写诗、不会画画,但它把一个基础但重要的任务——看懂文档——做到了很高的水平。而且开源、轻量、好用,这些特质让它从实验室走向了真正的应用场景。
百度的这次开源,也给国内AI公司打了个样:与其追着OpenAI做通用大模型,不如在垂直领域把一件事做到极致。
https://huggingface.co/baidu/Unlimited-OCR
本文地址:https://www.163264.com/13469
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~