

baichuan-7B是由百川智能开发的一个开源的大规模预训练模型。基于Transformer结构,在大约1.2万亿tokens上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
如果希望使用baichuan-7B(如进行推理、Finetune等),我们推荐使用配套代码库baichuan-7B。
- 在同尺寸模型中baichuan-7B达到了目前SOTA的水平,参考下面MMLU指标
- baichuan-7B使用自有的中英文双语语料进行训练,在中文上进行优化,在C-Eval达到SOTA水平
-
不同于LLaMA完全禁止商业使用,baichuan-7B使用更宽松的开源协议,允许用于商业目的
Hugging Face:https://huggingface.co/baichuan-inc/baichuan-7B
Github:https://github.com/baichuan-inc/baichuan-7B
Model Scope:https://modelscope.cn/models/baichuan-inc/baichuan-7B/summary
多个中文评估基准拿下7B最佳
为了验证模型的各项能力,baichuan-7B在C-Eval、AGIEval和Gaokao三个最具影响力的中文评估基准进行了综合评估,并且均获得了优异成绩,它已经成为同等参数规模下中文表现最优秀的原生预训练模型。
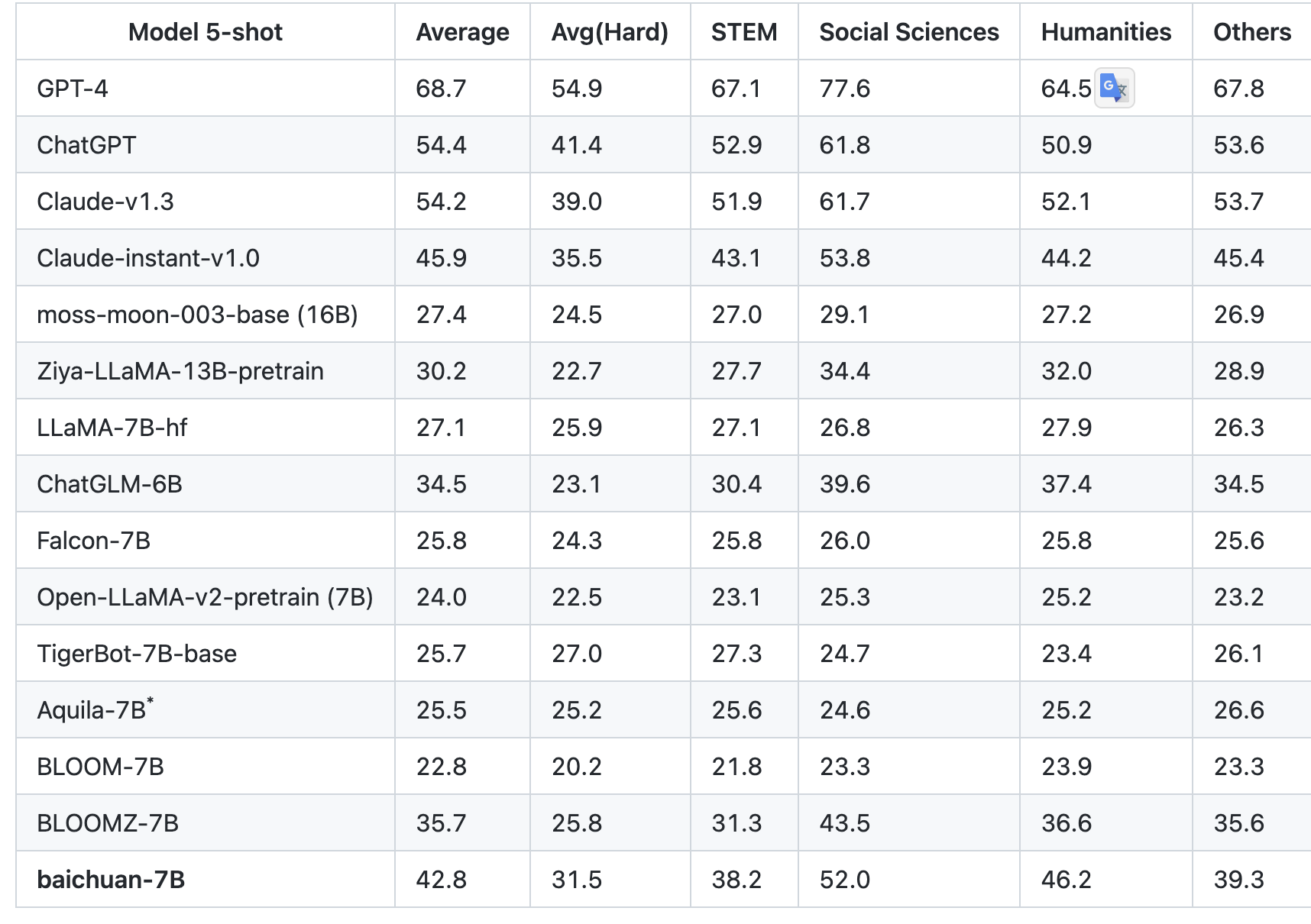
CEval数据集是一个全面的中文基础模型评测数据集,涵盖了52个学科和四个难度的级别。我们使用该数据集的dev集作为few-shot的来源,在test集上进行了5-shot测试。
本文地址:https://www.163264.com/4256
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
