

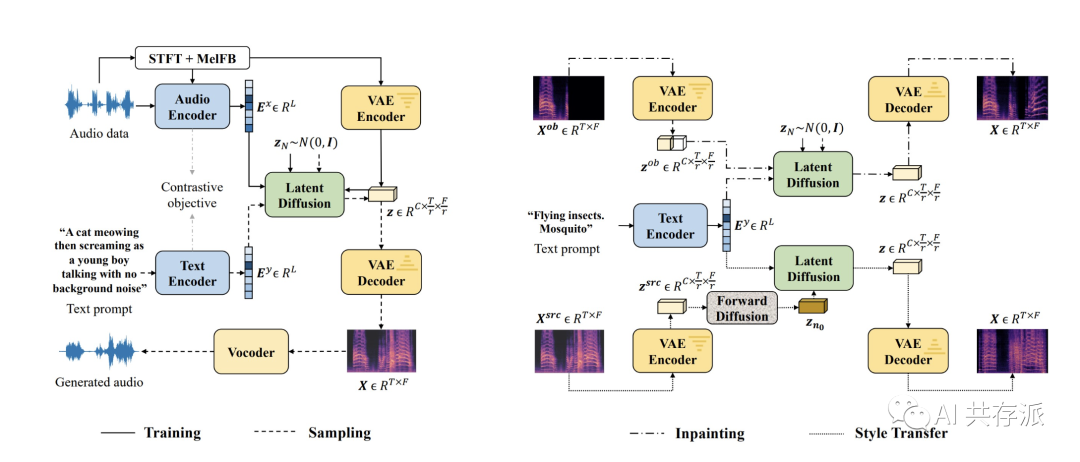
– Haohe Liu、Zehua Chen、Yi Yuan、Xinhao Mei、Xubo Liu、Danilo Mandic、Wenwu Wang和Mark D. Plumley等人提出了一种名为AudioLDM的文本转音频(TTA)系统,该系统建立在潜在空间上,通过对比语音-音频预训练(CLAP)潜变量来学习连续音频表示。
– AudioLDM在生成质量和计算效率方面具有优势,并在单个GPU上训练的情况下,通过客观和主观指标(如Frechet距离)实现了最先进的TTA性能。
– AudioLDM是第一个能够以零样本方式实现各种文本引导音频操作(如风格转换)的TTA系统。
– AudioLDM可以生成文本条件的音效、人声和音乐,并且在训练过程中不需要文本监督。
– AudioLDM的设计概述包括文本到音频生成和文本引导音频操作两部分,其中使用VAE学习的连续空间作为LDM的条件。
– 提供了一些音频示例,包括短音频样本、长音频样本、声学环境控制、材料控制、音高控制、时间顺序控制、标签到音频生成等。
– 还展示了使用ChatGPT文本提示进行TTA生成的示例,以及使用原始文本提示进行音频修复、风格转换和超分辨率的示例。
– 作者计划在确认数据相关的版权问题后发布预训练模型,并在GitHub上分享模型评估的代码,以便进行更容易的比较。
代码地址:
https://github.com/haoheliu/AudioLDM
体验地址:
https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation
喇叭声-儿童歌声
来源:https://mp.weixin.qq.com/s/3NkeiHLYkTalZ2_VVBDEDQ
本文地址:https://www.163264.com/4737
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
