

项目地址:
https://people.eecs.berkeley.edu/~evonne_ng/projects/audio2photoreal/
代码:
https://github.com/facebookresearch/audio2photoreal
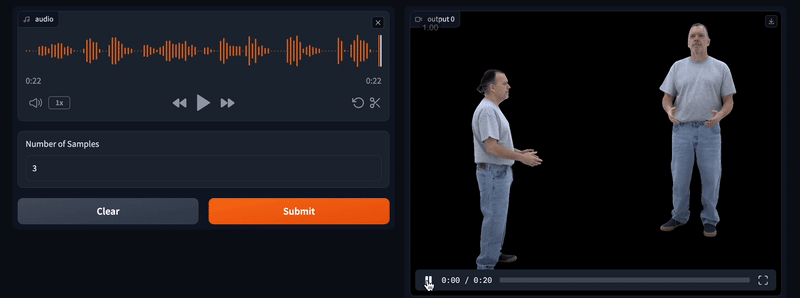
内容:1 Meta Reality Labs研究,2加利福尼亚大学伯克利分校。简而言之:从对话的音频中,我们生成相应的逼真面部、身体和手势。可推广性:头像是由作者的声音驱动的(而不是模型训练的演员)。摘要:我们提出了一个框架,用于生成根据对话动态进行手势的全身逼真头像。给定语音音频,我们输出个体的多种可能的手势运动,包括面部、身体和手部。我们方法的关键在于将向量量化的样本多样性的好处与扩散获得的高频细节相结合,以生成更具动态和表现力的运动。我们使用高度逼真的头像可视化生成的运动,可以表达手势中的重要细微差别(例如冷笑和嘲笑)。为了促进这一研究方向,我们介绍了一种首创的多视角对话数据集,可以进行逼真的重建。实验证明,我们的模型生成了适当且多样化的手势,优于扩散和仅使用向量量化的方法。此外,我们的感知评估突出了逼真性(与网格相比)在准确评估对话手势中的细微动作细节方面的重要性。代码和数据集将公开发布。概述:从对话的音频中,我们生成逼真的面部、身体和手势。方法:请按照编号视频的顺序了解我们的方法。要点:对于身体部分,我们的联合VQ +扩散方法使我们能够实现比仅使用其中之一更动态和尖峰的运动。
1.我们捕获了一个新颖丰富的对话数据集,可以进行逼真的重建。数据集在此处。
2.我们的运动模型由3个部分组成:面部运动模型、引导姿势预测器和身体运动模型。
3.给定音频和预训练的唇部回归器的输出,我们训练一个条件扩散模型来输出面部运动。
4.对于身体部分,我们将音频作为输入,并自回归地以1fps输出VQ-ed的引导姿势。
5.然后,我们将音频和引导姿势传入扩散模型,以30fps填充高频身体运动。
6.生成的面部和身体运动都传入我们训练的头像渲染器,生成逼真的头像。
7.完成!最终结果。结果:我们在下面的每个视频中突出显示了值得注意的时刻。要点:我们生成了尖峰、多样化的运动,如指点、手腕甩动、耸肩等。
我们的VQ +扩散方法允许样本之间更高的多样性。
1.引导姿势驱动扩散模型集成指向性动作。
2.扩散模型生成细微细节以传达不满(“嗯”脸、不屑的手腕甩动、转身)。3 + 4.我们的模型在相同的音频输入下生成了各种样本。比较:我们在下面的每个视频中突出显示了值得注意的时刻。要点:我们的方法生成的运动比之前的SOTA更具动态和表现力,并且比KNN或随机方法更具可信度。1.手腕甩动表示列举;讲故事时耸肩。2.强调“它们肯定有原因”时的手臂动作;指点以表达观点。
3.遵循对话和声音波动的一般手部扫动模式。
4.提问时指向;思考时向后移动头部;回答时手部向外运动。应用:可推广性:我们的方法适用于任意音频,例如从电视剪辑中获取的音频。动画:粗略的引导姿势可用于下游应用,如动作编辑。A/B感知评估:我们与真实情况或我们最强的基线LDA [Alexanderson et.al. 2023]进行比较。
逼真性的重要性:我们的方法在网格和逼真设置中都优于LDA [Alexanderson et.al. 2023]。有趣的是,当以逼真的方式可视化时,评估者从稍微偏向我们到强烈偏向我们(顶部行)。当我们将我们的方法与真实情况进行比较时,这种趋势继续存在(底部行)。虽然我们的方法在基于网格的渲染中与真实情况竞争,但在逼真领域中落后,43%的评估者强烈偏向真实情况而不是我们的方法。由于网格通常会遮挡细微的动作细节,因此很难准确评估手势中的细微差别,评估者对“不正确”的动作更宽容。我们的结果表明,逼真性对于准确评估对话运动至关重要。BibTeX @inproceedings 模板改编自Nerfies。
本文地址:https://www.163264.com/5957
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
