

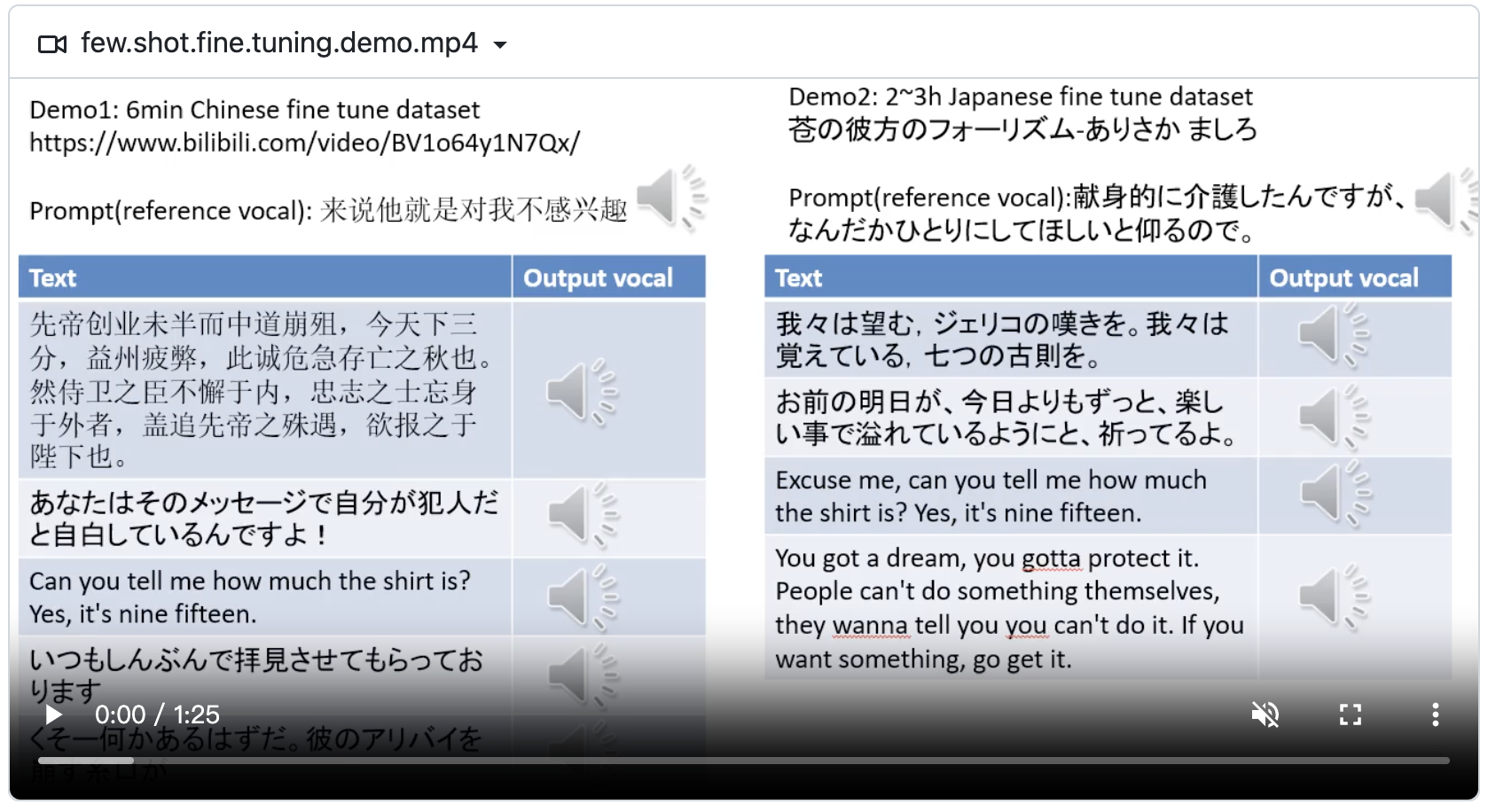
GPT-SoVITS是一个声音克隆和文本到语音转换的开源 Python RAG框架。
只需5秒的数据,它就可以模仿你的声音,只需1分钟的声音数据,就可以训练出一个高质量的TTS模型,完美克隆你的声音!
根据演示来看,它似乎是目前中文支持比较好的模型。
界面也很易用。
主要特点包括:
1. 零样本TTS:只需5秒的声音样本即可体验即时的文本到语音转换。
2. 少量样本训练:只需1分钟的训练数据即可微调模型,提高声音相似度和真实感。模仿出来的声音会更接近原声,听起来更自然。
3. 跨语言支持:支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
4. 易于使用的界面:集成了声音伴奏分离、自动训练集分割、中文语音识别和文本标签等工具,帮助初学者更容易地创建训练数据集和GPT/SoVITS模型。
5. 适用于不同操作系统:项目可以在不同的操作系统上安装和运行,包括Windows。
6. 预训练模型:项目提供了一些已经训练好的模型,你可以直接下载使用。
项目地址:
https://github.com/RVC-Boss/GPT-SoVITS
本文地址:https://www.163264.com/6207
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
