

Stable Audio 2.0 是由 Stability AI 推出的一款先进的音频生成模型,具有以下显著特点:
1. **高质量音频输出**:Stable Audio 2.0 能够从单一的自然语言提示生成长达三分钟、44.1 kHz 立体声的高质量完整音轨。
2. **文本到音频和音频到音频功能**:除了传统的文本到音频转换,用户还可以上传音频样本,并通过自然语言提示将其转换成各种声音效果。
3. **扩展的声音效果和风格转换**:这一更新增强了声音效果的生成和风格转换的能力,为艺术家和音乐家提供了更多的灵活性、控制力和提升的创作体验。
4. **完整的音乐结构**:Stable Audio 2.0 能够生成具有引子、发展和尾声等结构的完整歌曲,区别于其他同类模型。
5. **声音效果创作**:该模型加强了声音和音效的生产,提供了从简单的键盘敲击声到人群喧嚣或城市街道的嘈杂声等多种声音效果,为音频项目提供了新的提升方式。
6. **风格转换**:新功能允许在生成过程中无缝修改新生成或上传的音频,以适应项目特定的风格和基调。
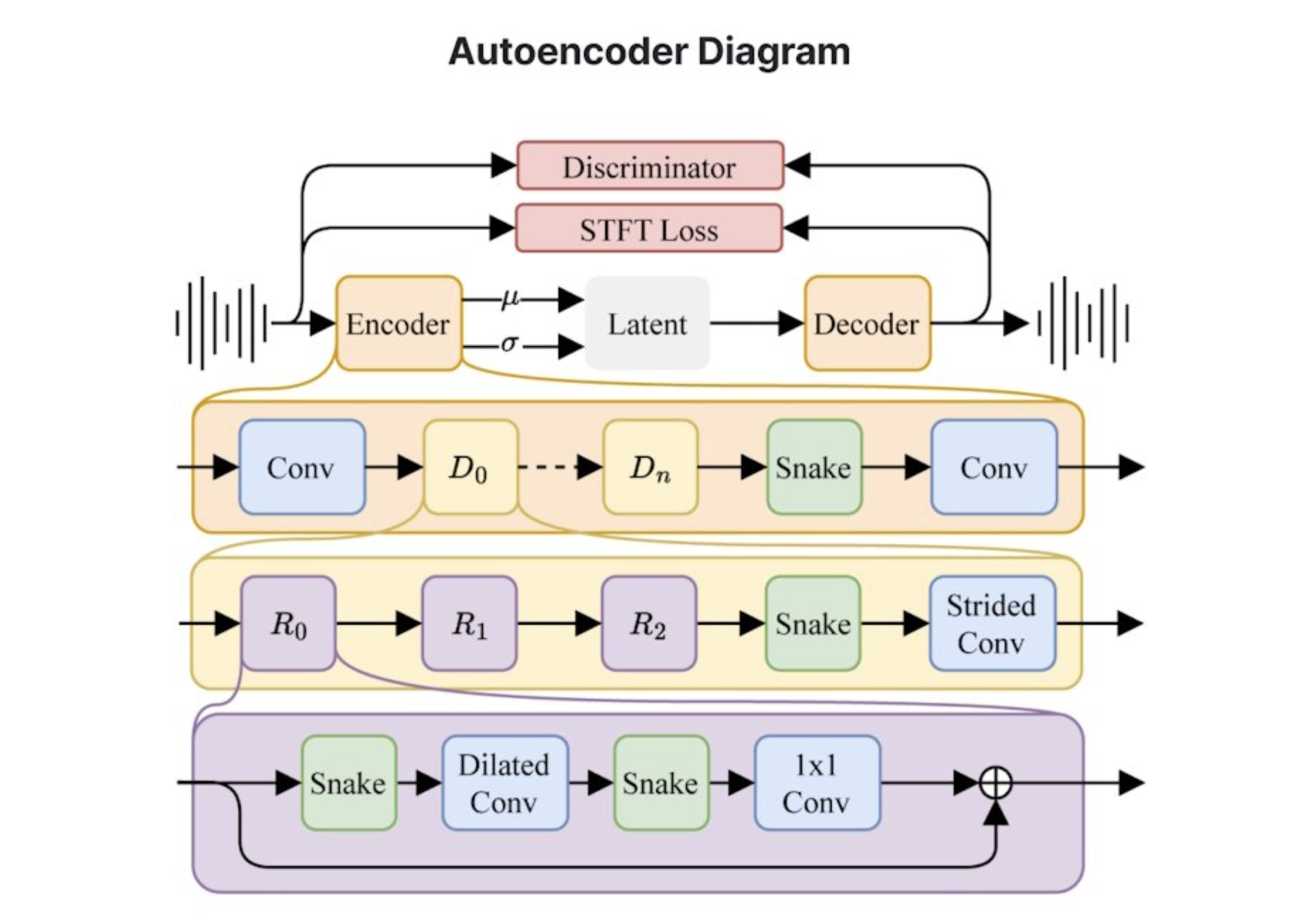
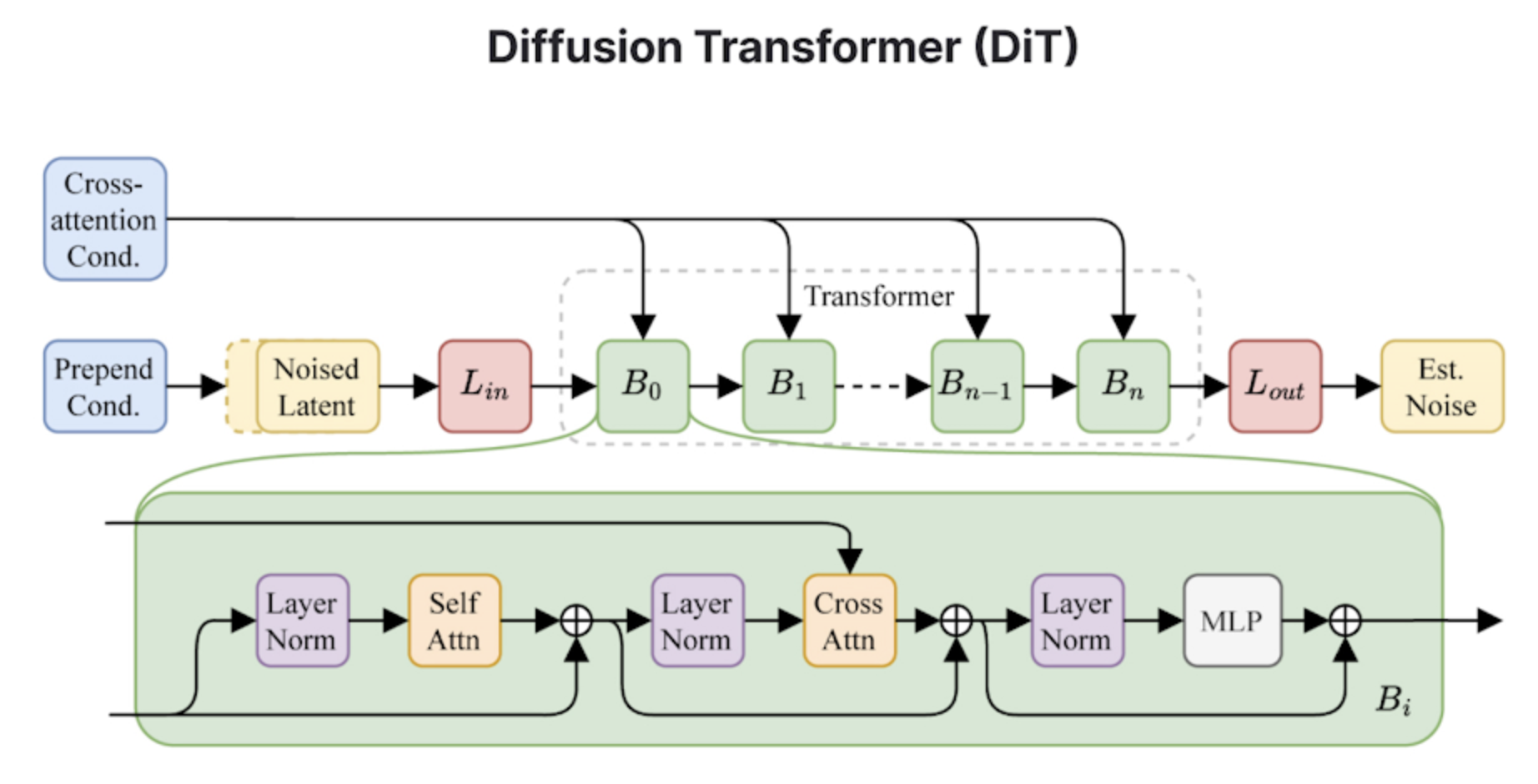
7. **专为生成完整音轨设计的架构**:Stable Audio 2.0 的潜在扩散模型专门设计用于生成具有连贯结构的完整音轨。为此,系统的所有组件都经过改进,以提高长期性能。
8. **高压缩自动编码器和扩散变换器**:新模型采用了一种高压缩的自动编码器来压缩原始音频波形,并使用了类似于 Stable Diffusion 3 中的扩散变换器(DiT),以更有效地处理长序列数据。
9. **研究与发展**:Stable Audio 2.0 的研发团队致力于技术的进步,未来将发布研究论文,提供更多技术细节。
Stable Audio 2.0 作为市场上最先进音频模型之一,不仅为艺术家和音乐家提供了强大的创作工具,同时也推动了人工智能在音乐创作领域的应用和发展。
地址:
https://stability.ai/news/stable-audio-2-0
本文地址:https://www.163264.com/6790
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
