

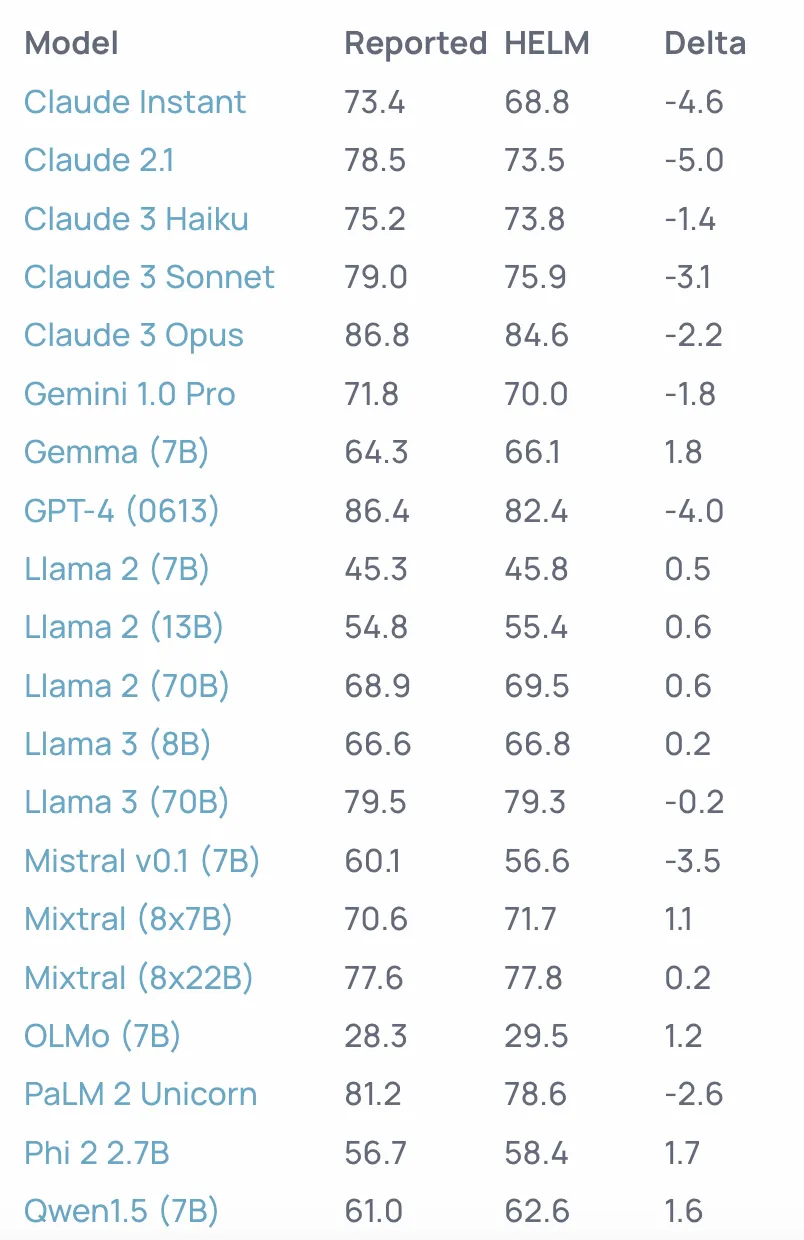
尽管Massive Multitask Language Understanding(MMLU)基准测试备受关注,但模型创建者报告的MMLU分数经常以不一致或有问题的方式产生,这阻碍了它们的可比性。为了解决这个问题,我们引入了HELM MMLU,一个排行榜,展示了评估各种语言模型在MMLU上的结果。我们的评估结果包括简单和标准化的提示,每个57个主题的准确性分解,以及所有原始提示和预测的完全透明度。
结果:通过使用HELM对这些模型进行评估,我们得到了以下MMLU分数。我们的MMLU分数经常接近原始模型论文中报告的MMLU分数,但我们的一些分数与原始报告的分数相差多达5.0个百分点。HELM MMLU排行榜的结果还包括所有原始提示和预测的完全透明度,允许用户深入了解每个模型请求和每次模型评估运行的请求。值得注意的是,HELM MMLU排行榜上的MMLU分数通常与HELM Lite排行榜上的MMLU分数不同,因为HELM MMLU排行榜使用所有57个主题进行评估,而HELM Lite排行榜只使用五个主题。
原文地址:
https://crfm.stanford.edu/2024/05/01/helm-mmlu.html
本文地址:https://www.163264.com/7951
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
