


全文总结
本文主要介绍了一种名为 Matryoshka Diffusion Models(MDM)的端到端框架,用于高分辨率图像和视频合成。指出扩散模型在生成高质量图像和视频方面表现出色,但在高维空间学习存在挑战,现有方法常采用训练级联模型,而本文提出的 MDM 采用多尺度联合扩散过程,小尺度模型嵌套在大尺度内,促进了特征共享和架构的渐进式增长,在多个基准上展示了有效性,包括 ImageNet 等标准数据集以及高分辨率的文本到图像和文本到视频应用,该论文被 ICML 2024 的 Foundation Models in the Wild 研讨会接收。
重要亮点
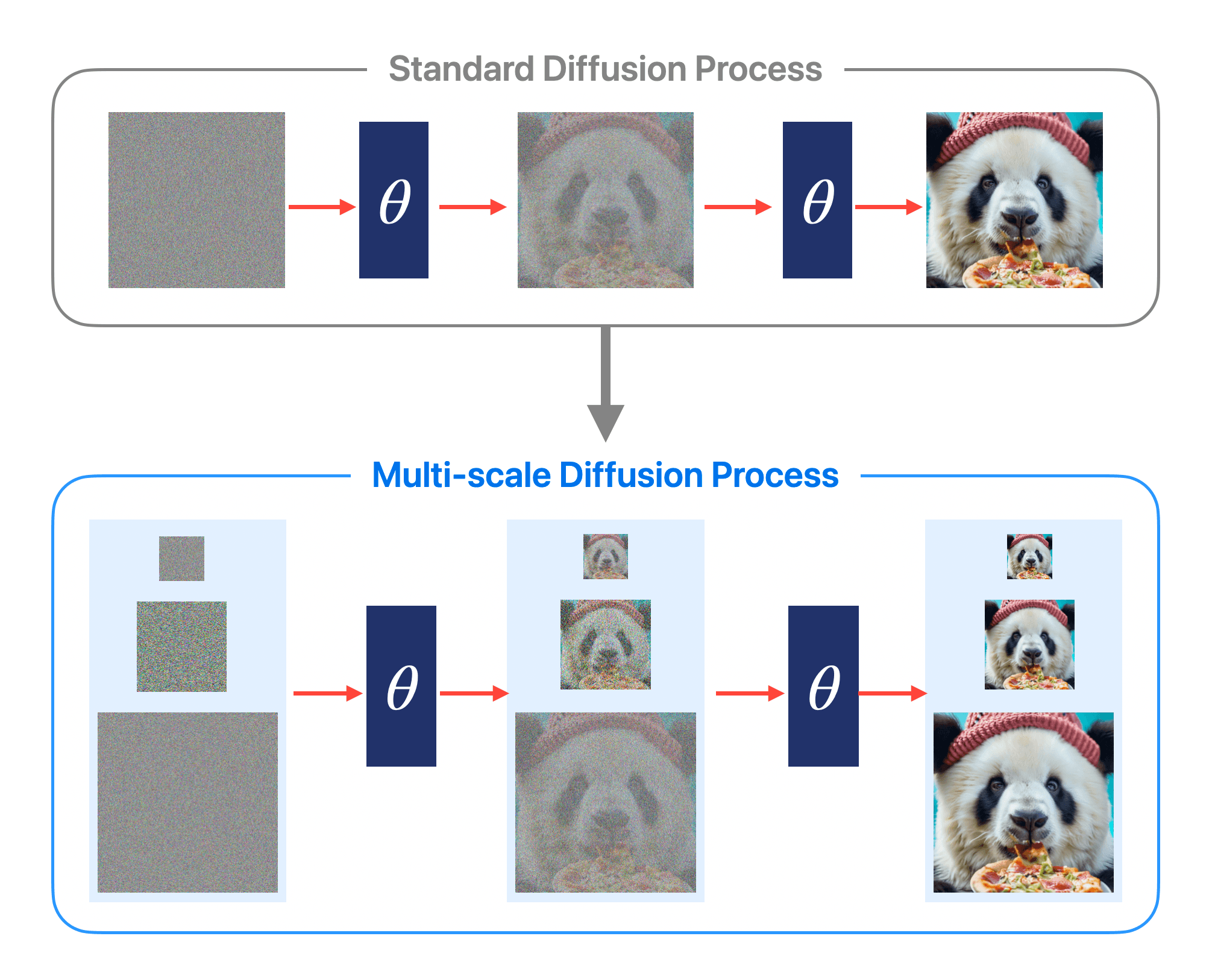
- 扩散模型的现状:在生成高质量图像和视频方面表现出色,但在高维空间学习面临计算和优化挑战。
- Matryoshka Diffusion Models(MDM)的特点:端到端框架,采用多尺度联合扩散过程,小尺度模型嵌套在大尺度内,便于特征共享和架构渐进式增长。
- MDM 的效果:在多个基准上有效,如在 ImageNet 和 COCO 上取得了一定的 FID 成绩。
- MDM 的分辨率能力:能训练分辨率高达 1024×1024 像素且具有三个嵌套尺度的单个像素空间模型。
- 论文的接收情况:被 ICML 2024 的 Foundation Models in the Wild 研讨会接收。
地址:
https://machinelearning.apple.com/research/matryoshka-diffusion-models
本文地址:https://www.163264.com/9095
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
