DeepSeek-Prover-V1 展示了大模型在数学定理证明领域的潜力,通过将数学问题转换为 Lean 编程语言,帮助数学家严格验证证明正确性。
今天,DeepSeek 开源 Prover-V1.5 版本,引入了类似 AlphaGo 的强化学习系统,模型通过自我迭代和 Lean 证明器监督,构建了一个“围棋”式的学习环境。
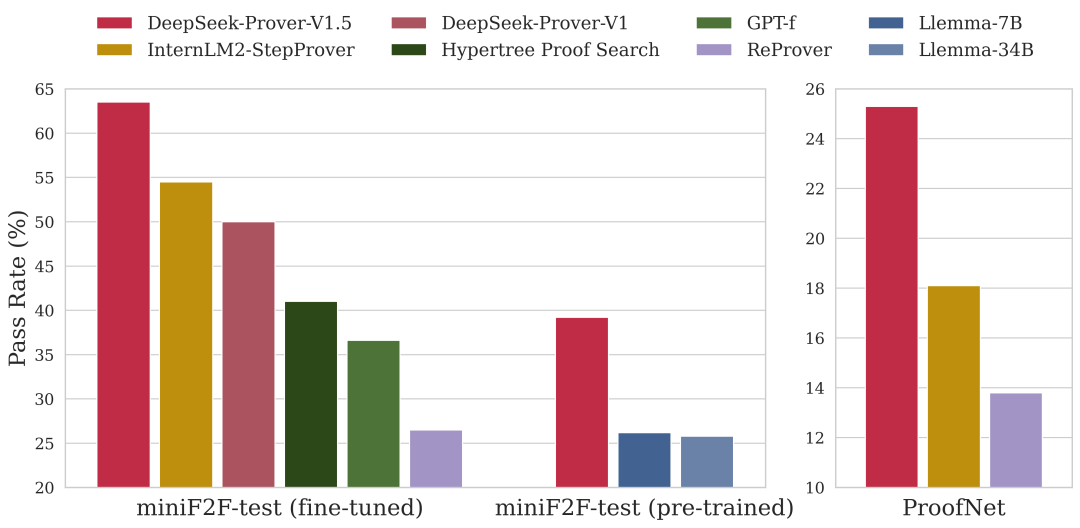
最终,仅 7B 参数规模的 Prover-V1.5,在高中(miniF2F)和大学(ProofNet)数学定理证明测试中分别达到了 63.5% 和 25.3% 的成功率,超越了多款开源模型(InternLM2-StepProver、Llemma)。
 Highlights
Highlights
-
数据:使用 DeepSeek-Coder-V2 合成自然语言思维链标注数据,结合 Lean 证明器标注的中间状态信息,将模型的形式化证明能力与自然语言推理对齐,同时满足程序验证的要求。
-
训练:以 Lean 证明器的验证结果直接作为奖励信号,使用 GRPO 算法对模型进行强化学习训练。
-
蒙特卡洛树搜索:引入 RMaxTS 算法,激励探索行为以解决证明搜索中的奖励稀疏问题,增强模型灵活生成多样化证明的能力。
-
实验结果:在高中水平的 miniF2F 和大学本科水平的 ProofNet 基准测试中取得了新的 SOTA,显著超越了所有现有模型。
论文地址:https://arxiv.org/abs/2408.08152
模型下载:https://huggingface.co/deepseek-ai
GitHub 主页:https://github.com/deepseek-ai/DeepSeek-Prover-V1.5
模型训练
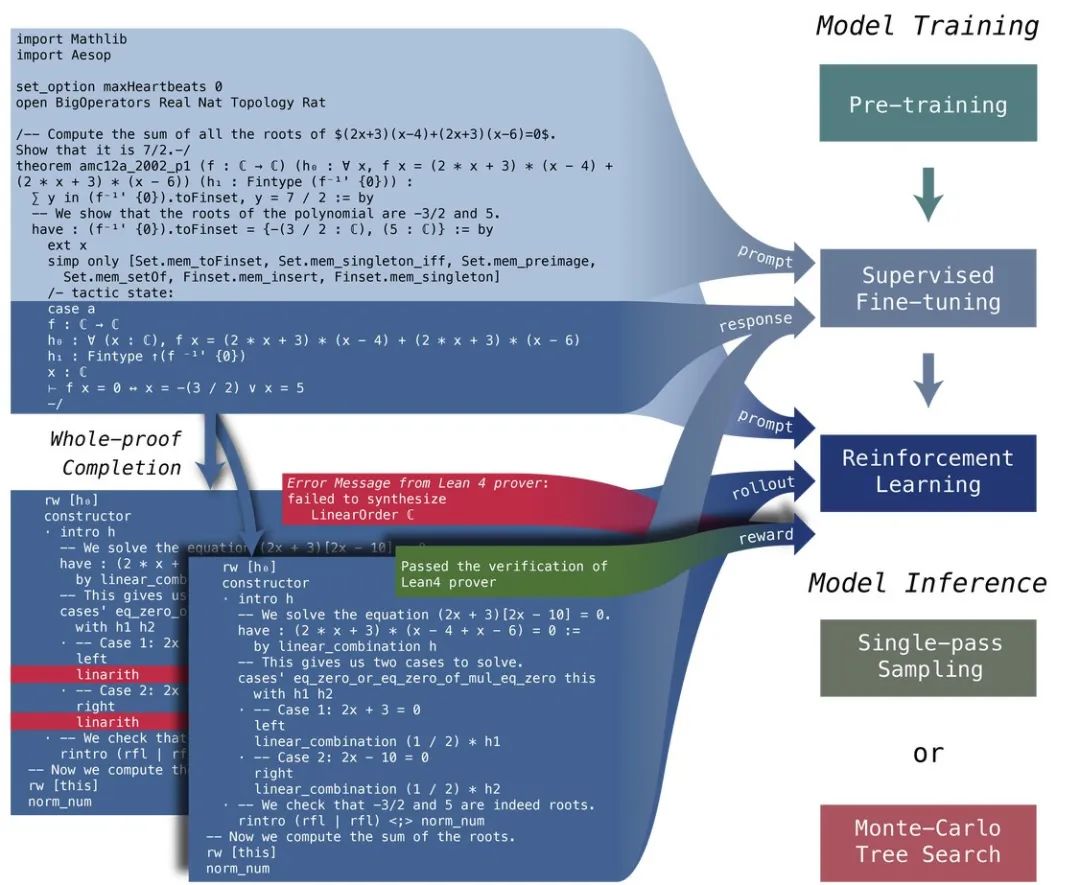
在高质量的数学和代码数据上进行进一步的预训练,特别关注 Lean、Isabelle 和 Metamath 等定理证明语言,以提高模型在形式化数学领域的通用能力。
已有工作大多聚焦于仅仅生成下一个证明步骤,而 DeepSeek-Prover-V1.5 则选择了更为困难的完整证明生成的训练目标。此外,在 DeepSeek-Prover-V1 合成的大规模定理证明数据的基础上,利用 DeepSeek-Coder-V2 合成自然语言的思维链数据标注,促使模型兼顾自然语言推理与形式化定理证明。
抽取微调数据中的定理内容作为输入,使用微调后的模型生成多个完整的证明候选项,然后利用 Lean 证明器对其正确性进行检验。将验证结果作为二元奖励信号,强化学习训练进一步增强了模型与验证系统形式规范的一致性。
三阶段模型权重均已开源。
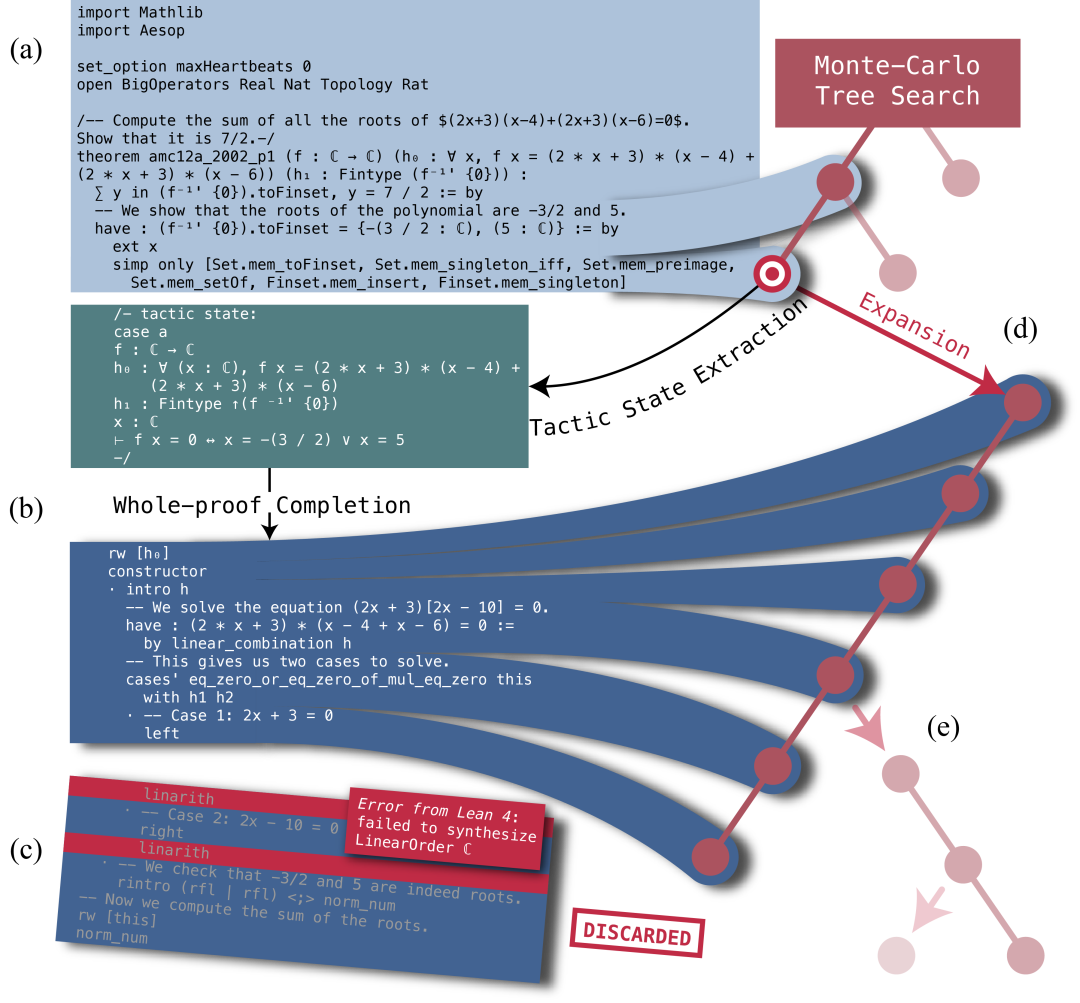
蒙特卡洛树搜索
DeepSeek-Prover-V1.5 将定理证明中的蒙特卡洛树搜索从单一证明预测推广至完整证明生成,为此特别引入了“截断-恢复”的机制来进行树节点的扩展:
(a) 选择一个节点进行扩展,追踪其对应的证明代码前缀,其中包括文件头、初始声明以及所有祖先节点中已经成功应用的 tactics。
(b) 模型基于这个代码前缀和 Lean 证明器返回的 tactic state 生成后续完整证明。
(c) Lean 4 证明器验证组合后的证明代码(前缀和新生成的代码)。如果没有发现错误,树搜索过程终止。如果检测到错误,我们在第一个错误消息处截断新生成的代码,丢弃后续代码,并将成功部分解析为 tactics。
(d) 每个 tactic 作为新节点添加到搜索树中,在选定的节点之后扩展出一串后继节点。
(e) 完成树节点扩展后,选择另一个候选节点并进行下一轮扩展。
这个过程重复进行,直到找到正确的证明或达到采样数上限。
此外,DeepSeek-Prover-V1.5 结合了一种新的蒙特卡洛树搜索算法——RMaxTS,建立了内在奖励机制以引导搜索流程中生成的证明产生多样化的 tactic state,利用 Lean 证明器的反馈来帮助减少冗余生成,提高采样效率。
模型表现
下表展示了各模型在 miniF2F-test 基准测试中的表现。该基准由高中水平的数学习题和竞赛题(如 AMC、AIME 和 IMO)在 Lean 定理证明语言中形式化而成。在直接生成完整证明的任务中,DeepSeek-Prover-V1.5 以 60.2% 的证明通过率显著领先其他方法。当结合 RMaxTS 树搜索技术时,其性能更是提升至 63.5% 的通过率。
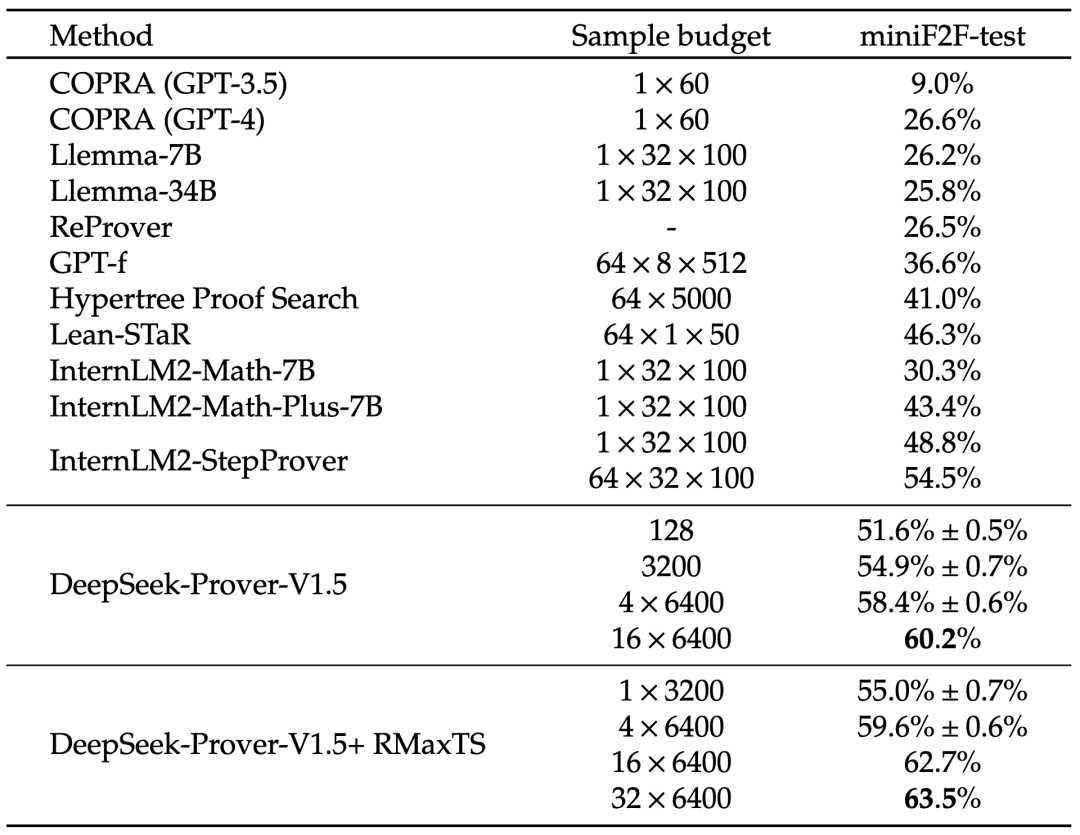
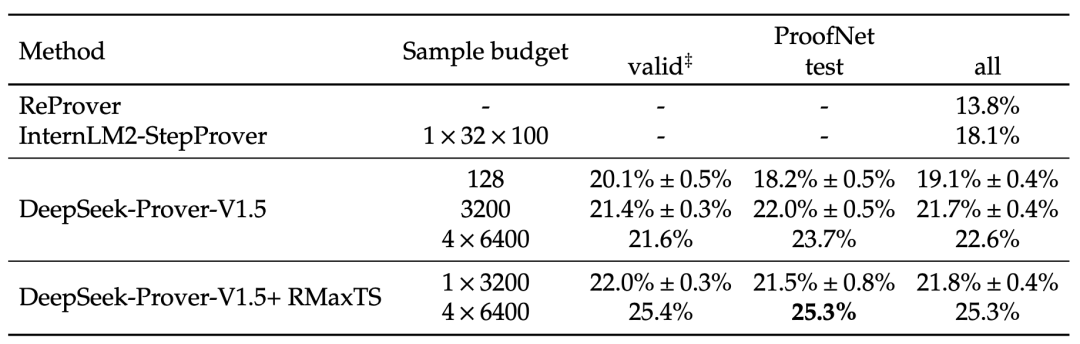
下表呈现了各模型在 ProofNet 基准测试上的成绩。该基准精选了数学本科主流教材中的习题,涵盖实分析、复分析、线性代数、抽象代数和拓扑学等核心分支。在直接生成证明的任务中,DeepSeek-Prover-V1.5 再次以 22.6% 的通过率显著超越其他方法。运用 RMaxTS 树搜索后,其表现进一步提升至 25.3% 的通过率。
更多方法细节和分析实验见论文,阅读原文即可获取。
About Future
随着人工智能技术的不断进步,数学定理证明领域正迎来一场革命。DeepSeek-Prover-V1.5的最新成果表明,AI能够凭借其强大的逻辑推理能力独立解决多步骤的复杂证明问题。这一突破不仅展示了AI在数学定理证明中的巨大潜力,还为未来开发能够自主提出并证明完整数学理论的AI系统奠定了坚实基础。这些系统将有助于人类数学家更深入地探索数学真理,推动数学研究的前沿发展。
来源:https://mp.weixin.qq.com/s/O4aC9dvJC30sfSQyYgbcow
本文地址:https://www.163264.com/9377



 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
