

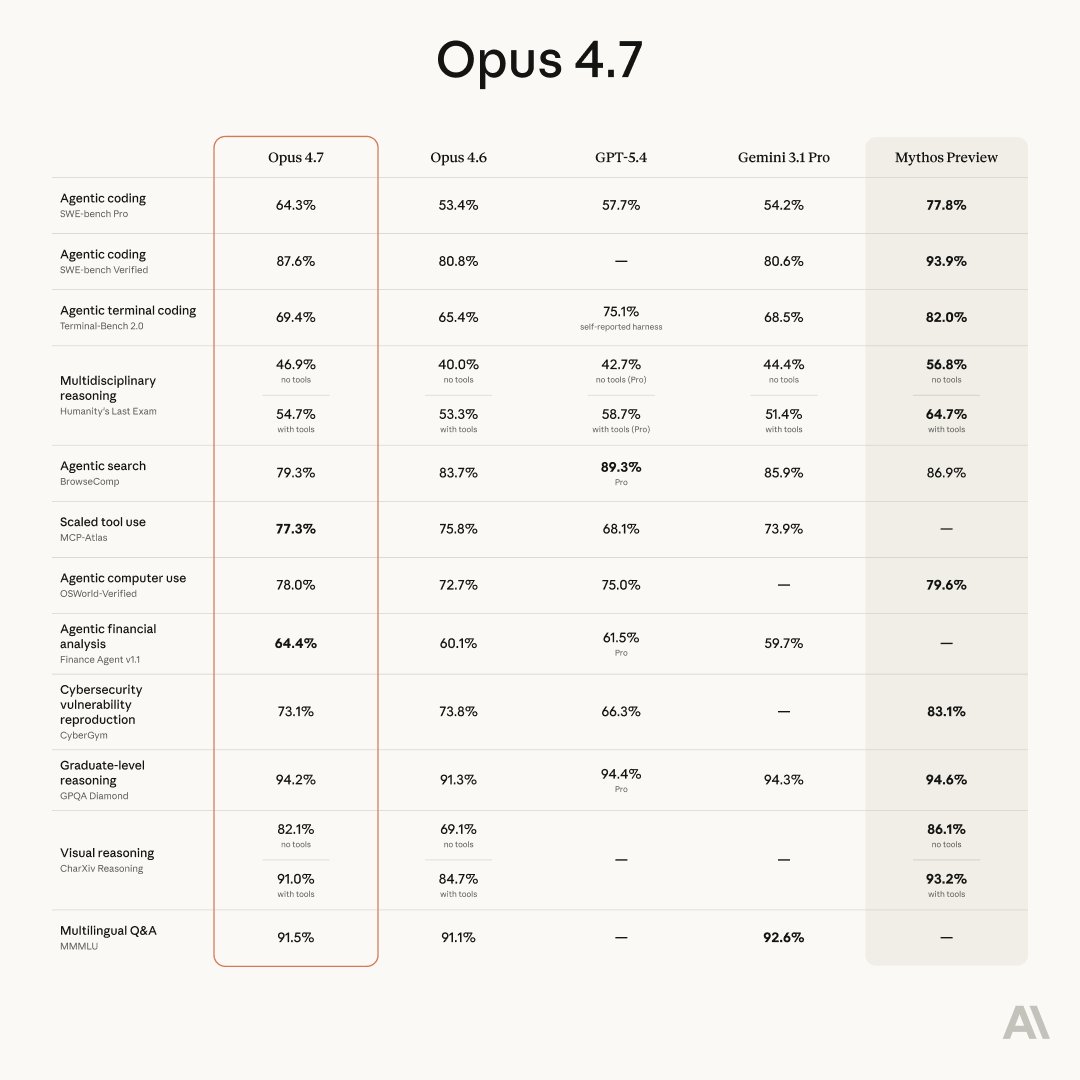
Anthropic 今日宣布 Claude Opus 4.7 正式发布并全面可用。作为 Opus 4.6 的直接升级版本,Opus 4.7 在高级软件工程能力方面实现了显著提升,尤其在处理最困难的任务时表现更加出色。
核心升级亮点
1. 软件工程能力跃升
Opus 4.7 让用户能够将最困难的编码工作放心地交给它处理——这类工作以前需要密切监督。该模型能够以严谨和一致性处理复杂、长时间运行的任务,精确遵循指令,并在报告结果之前设计验证自身输出的方法。
2. 视觉能力翻倍提升
Opus 4.7 的视觉能力有大幅提升:它可以接受分辨率高达 2,576 像素(长边)的图像,像素数量是之前 Claude 模型的三倍以上。这开启了一系列依赖精细视觉细节的多模态应用场景:计算机使用代理读取密集的屏幕截图、从复杂图表中提取数据,以及需要像素级精确引用的工作。
3. 更强的创造力与专业表现
在完成专业任务时,Opus 4.7 更具品味和创造力,能够制作更高质量的界面、幻灯片和文档。相比 Opus 4.6,它在多个基准测试中表现更优。
网络安全防护措施
作为上周宣布的 Project Glasswing 计划的一部分,Opus 4.7 成为首个部署新网络安全防护措施的模型。这些防护措施能够自动检测并阻止表明被禁止或高风险网络安全用途的请求。Anthropic 表示,从实际部署中收集的经验将帮助其实现 Mythos 级模型的广泛发布目标。
希望将 Opus 4.7 用于合法网络安全目的(如漏洞研究、渗透测试和红队演练)的安全专业人员,可以申请加入新的 Cyber Verification Program。
业界积极反馈
来自 Cursor、Replit、Vercel、Databricks、Notion 等公司的早期测试者对 Opus 4.7 给予了高度评价:
- Cursor:在 CursorBench 上,Opus 4.7 的能力有实质性提升,通过率从 58% 提升至 70%
- Replit:Opus 4.7 是一项简单的升级决策,在分析日志、查找 bug 和提出修复建议等日常任务中更加高效和精确
- Vercel:在一次性编码任务上表现出色,比 Opus 4.6 更正确、更完整,对自己的局限性也更加诚实
- Notion:对于复杂多步骤工作流程,Opus 4.7 是明显的进步,工具调用准确率提升两位数,错误率降低三分之一
- Databricks:在 OfficeQA Pro 上,文档推理能力显著增强,处理源信息时的错误比 Opus 4.6 减少 21%
新增功能
- 新增 xhigh 努力级别:介于 high 和 max 之间的额外高努力级别,让用户能够更精细地控制推理与延迟之间的权衡
- Claude Code 升级:默认努力级别提升至 xhigh,新增 /ultrareview 斜杠命令用于代码审查,Max 用户可使用 auto 模式
- 任务预算(公测):开发者可以通过任务预算指导 Claude 的 token 消耗,使其能够在更长的运行中优先处理工作
定价与可用性
Opus 4.7 现已通过所有 Claude 产品、API、Amazon Bedrock、Google Cloud Vertex AI 和 Microsoft Foundry 提供。定价与 Opus 4.6 保持一致:每百万输入 token 5 美元,每百万输出 token 25 美元。
本文地址:https://www.163264.com/10923
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~