

京东最近搞了个大动作——正式开源了JoyAI-VL-Interaction实时视频视觉语言交互模型。这玩意儿号称全球首个全栈开源的视觉交互模型,连整套部署系统都一并放出来了。
传统AI的痛点:太被动了
现在市面上的多模态模型基本都是”你问我答”的模式,用户不提问,AI就傻站着。这种被动式交互在实时监控、直播讲解这些场景里根本不够用。
JoyAI的三大革新
1. 主动自主判断
这个模型能持续读取摄像头、监控画面、直播流,自己识别关键事件并主动提醒。没情况的时候自动静默,不需要人一直盯着。比如监控里发现火情、老人摔倒,它能立刻预警。
2. 低延迟实时响应
面向正在发生的画面做流式处理,而不是等视频全部传完再分析。安防、实时翻译、直播讲解这些对时效性要求高的场景,终于有解了。
3. 前后台协作
遇到复杂推理、代码生成、工具调用这类重任务时,可以扔给后台Agent处理,前台模型继续盯着画面不中断,任务完成后无缝接续。
全栈开源,不只是放了个模型
京东这次开源的诚意很足——模型权重、专属交互数据集、完整训练方案、全套可部署工程框架全都有。支持灵活替换语音模块、可视化界面、第三方Agent与业务接口。
兼容摄像头、监控流、直播流多路输入,自带长期记忆、语音收发、vLLM快速部署能力。能快速搭建各种实景AI工具:居家看护、安防预警、直播解说、电商导购、智能眼镜辅助、工业操作指导等。
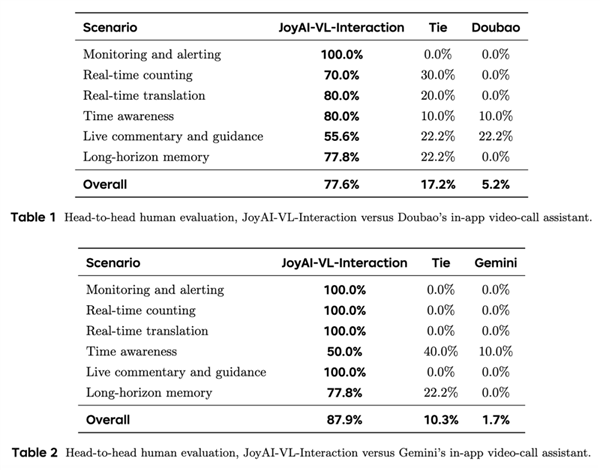
实测数据很能打
在覆盖监控预警、实时计数、实时翻译、直播解说等58组真人盲测中:
- 对比豆包视频交互助手,整体胜率77.6%
- 对比Gemini视频交互助手,整体胜率87.9%
- 安防预警场景对两款竞品达成100%胜率
核心优势在于交互模型的自主交互性是内建的,不是靠外部触发。这种”长在模型内部”的能力,让它在实时场景里天然更灵活。
目前模型已原生适配vLLM-Omni,开发者可以直接上手部署。
本文地址:https://www.163264.com/13213
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 