


ImageBind将多种数据流联系在一起,包括文本、音频、视觉数据、深度信息、温度和运动读数。
Meta公司公布了一个新的开源人工智能模型ImageBind,将多种数据流联系在一起,包括文本、音频、视觉数据、温度和运动读数等。
这个模型目前只是研究项目,没有直接的消费者用户或实际应用,但它指出了生成式人工智能系统的未来,可以创造沉浸式多感官体验,并表明在OpenAI和谷歌等竞争对手变得越来越神秘的时候,Meta继续对外分享人工智能研究。
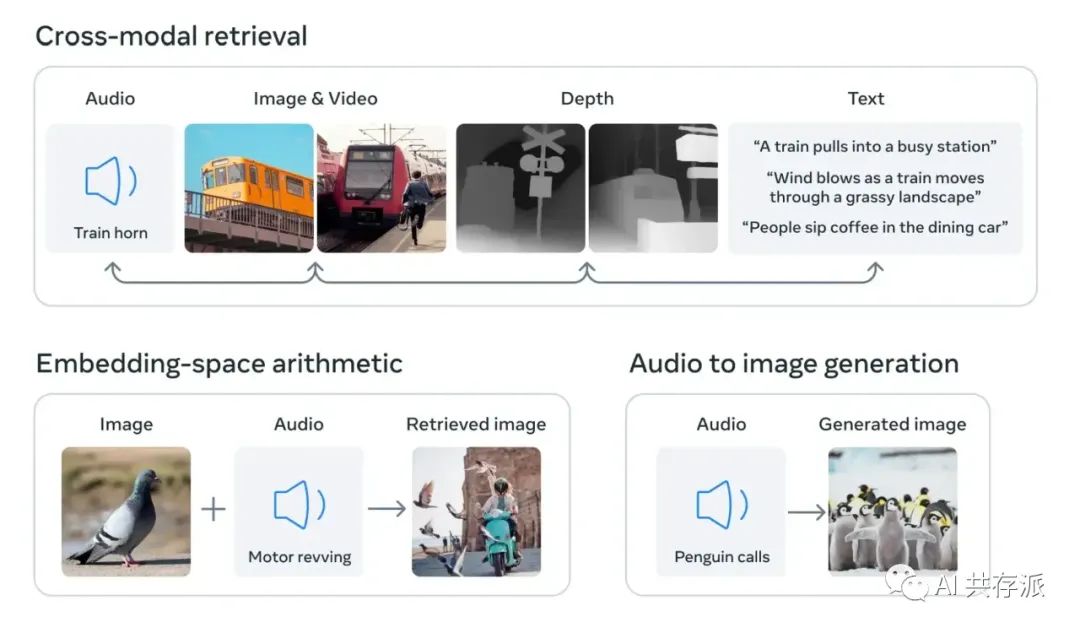
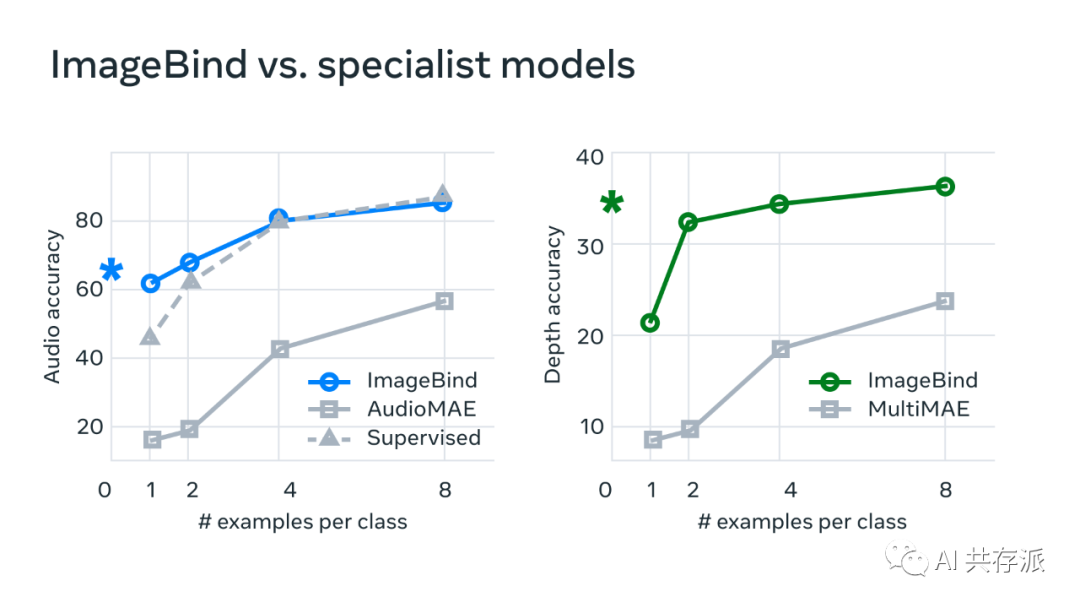
Facebook 这个 ImageBind太牛逼了吧 就像论文中说的:One Embedding Space To Bind Them All 这是要搞模型元宇宙吗? 可以将文本、音频、视觉、温度还有运动数据流串联在一起,形成一个单一的 embedding space,可以让模型能从多维度来理解世界。
官方原文:
https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
来源:https://mp.weixin.qq.com/s/L5HeH_bXPIgDqlw_W4vqnw
本文地址:https://www.163264.com/3153
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
