

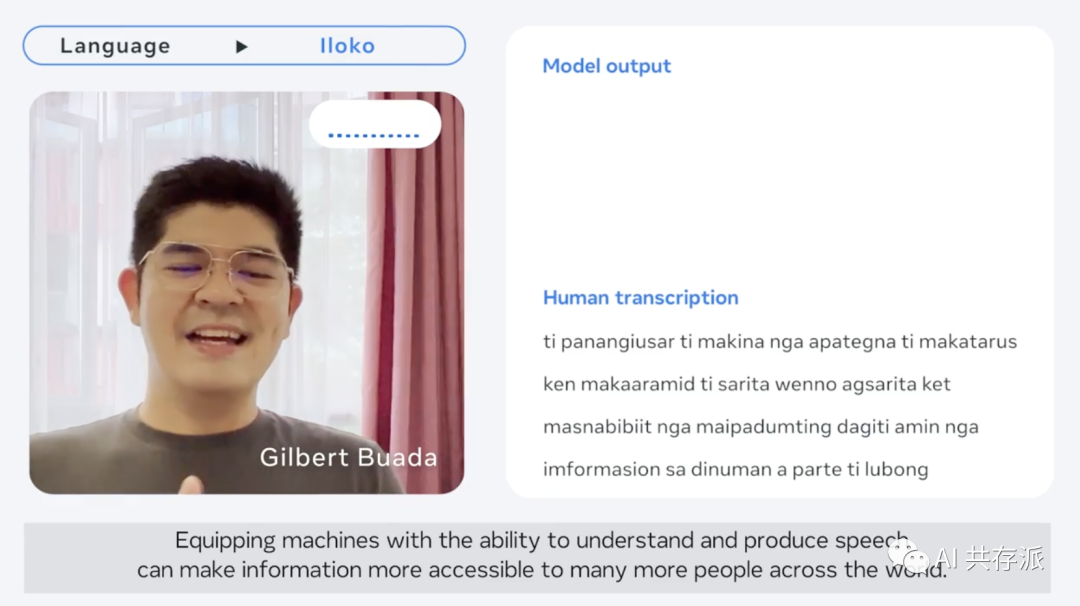
Meta公司最近推出了 Massively Multilingual Speech (MMS) 项目,为1100多种语言提供了先进的语言转录和语音合成服务,同时还支持将近4000多种未标记的口语。
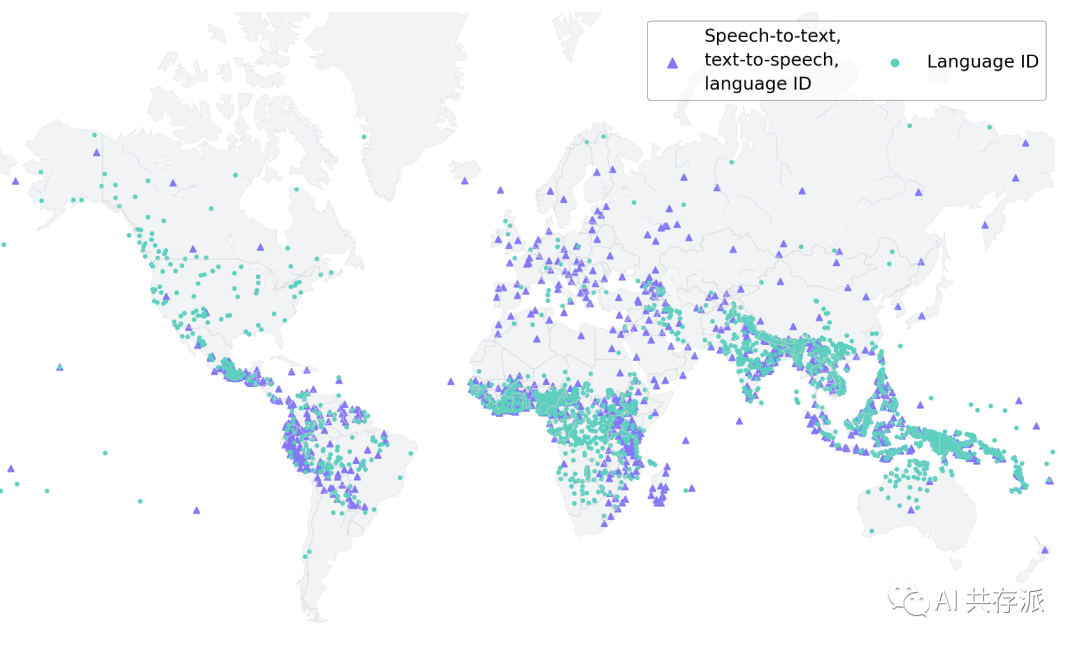
Meta整合了wav2vec 2.0自我监督学习模型和一个新数据集,并进行了实际测量。结果表明,MMS比现有模型性能更好,支持的语言数量是原有模型的10倍。该项目的成功关键在于引入了一个庞大的音频数据集,其中包含了1100多种不同的语言读新约圣经的语音内容。

Meta表示,使用该音频数据集生成的语音模型在男性和女性的语音上表现同样出色。
MMS:大规模多语言语音。
– 可以用 1100 种语言进行 speech2text 和文本语音。
– 可以识别 4000 种口头语言。
– 在 CC-BY-NC 4.0 许可下可用的代码和模型。
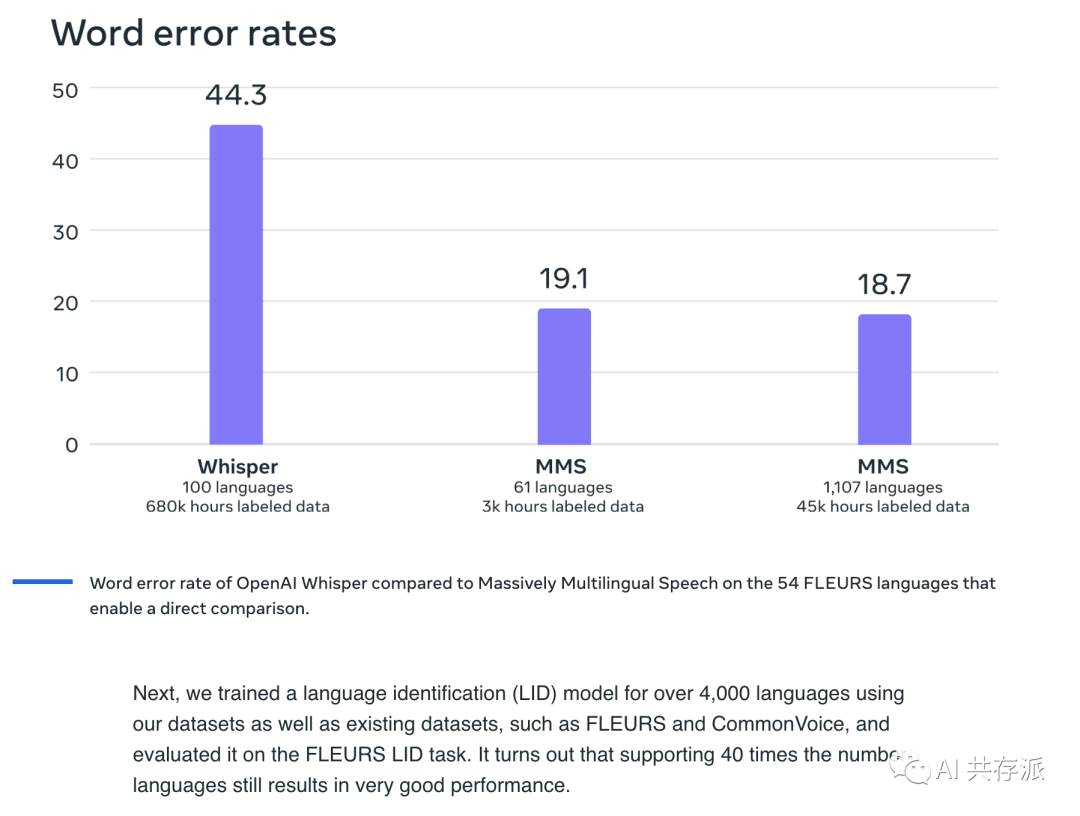
– Meta 在文档中提到比 Whisper 的错误率低了 50%
项目地址:
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
原文:
https://ai.facebook.com/blog/multilingual-model-speech-recognition/
来源:https://mp.weixin.qq.com/s/nt7MKNyIcvZoe2RtcMS0Mw
本文地址:https://www.163264.com/3491
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
