

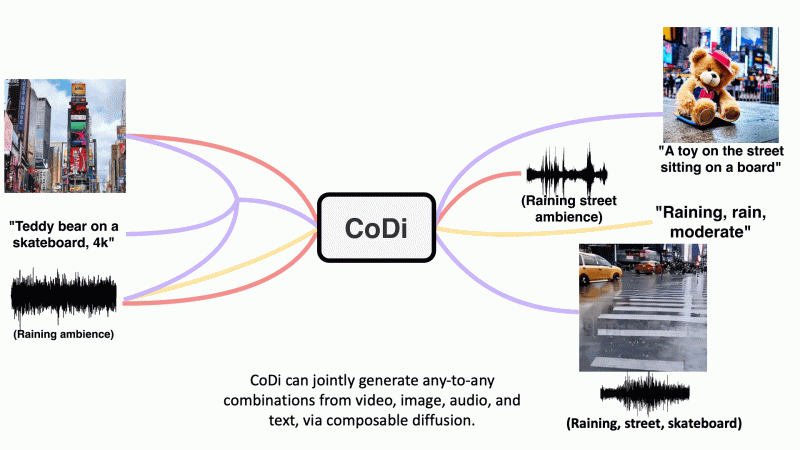
– CoDi是一种生成模型,可以从任意输入模态的任意组合中生成任意组合的输出模态。
– CoDi可以并行生成多个模态,其输入不仅限于文本或图像等子集模态。
– CoDi在输入和输出空间中对齐模态,可以自由地在任意输入组合上进行条件生成,并生成任何组合的模态,即使它们不在训练数据中。
– CoDi采用可组合的生成策略,通过在扩散过程中建立共享的多模态空间来桥接对齐,实现交织模态的同步生成,例如时间对齐的视频和音频。
– CoDi实现了强大的联合模态生成质量,并优于或与单模态合成的最新技术水平相当。
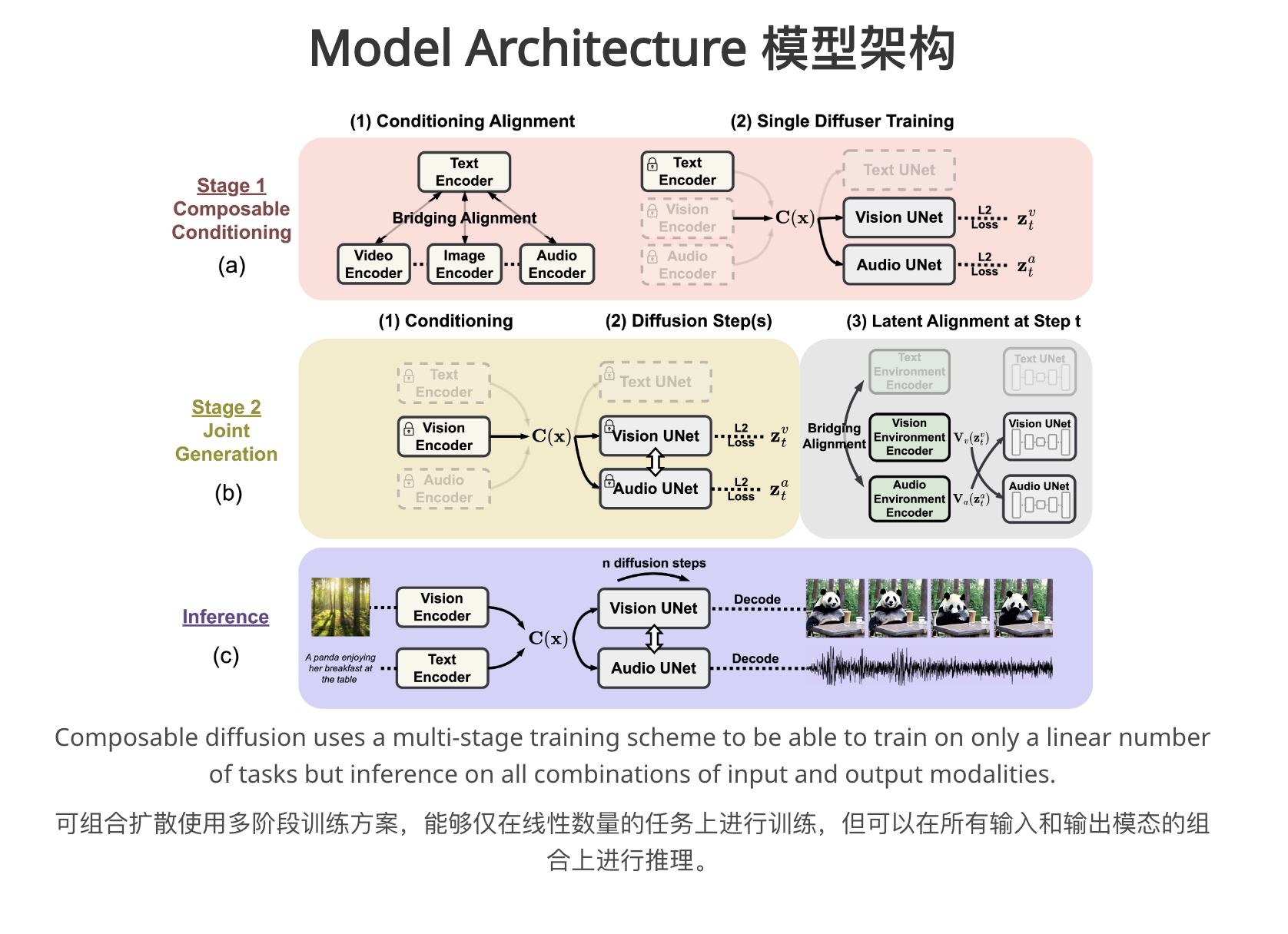
– CoDi使用多阶段训练方案,能够仅训练线性数量的任务,但推理所有输入和输出模态的组合。
– CoDi有三个模型:多输出联合生成模型、多重调节模型和单对单生成模型。
– 多输出联合生成模型接受单个或多个提示,包括视频、图像、文本或音频,生成多个对齐的输出,如带有伴奏的视频。
– 多重调节模型接受多个输入,包括视频、图像、文本或音频,生成输出。
– 单对单生成模型接受单个提示,包括视频、图像、文本或音频,生成单个输出。
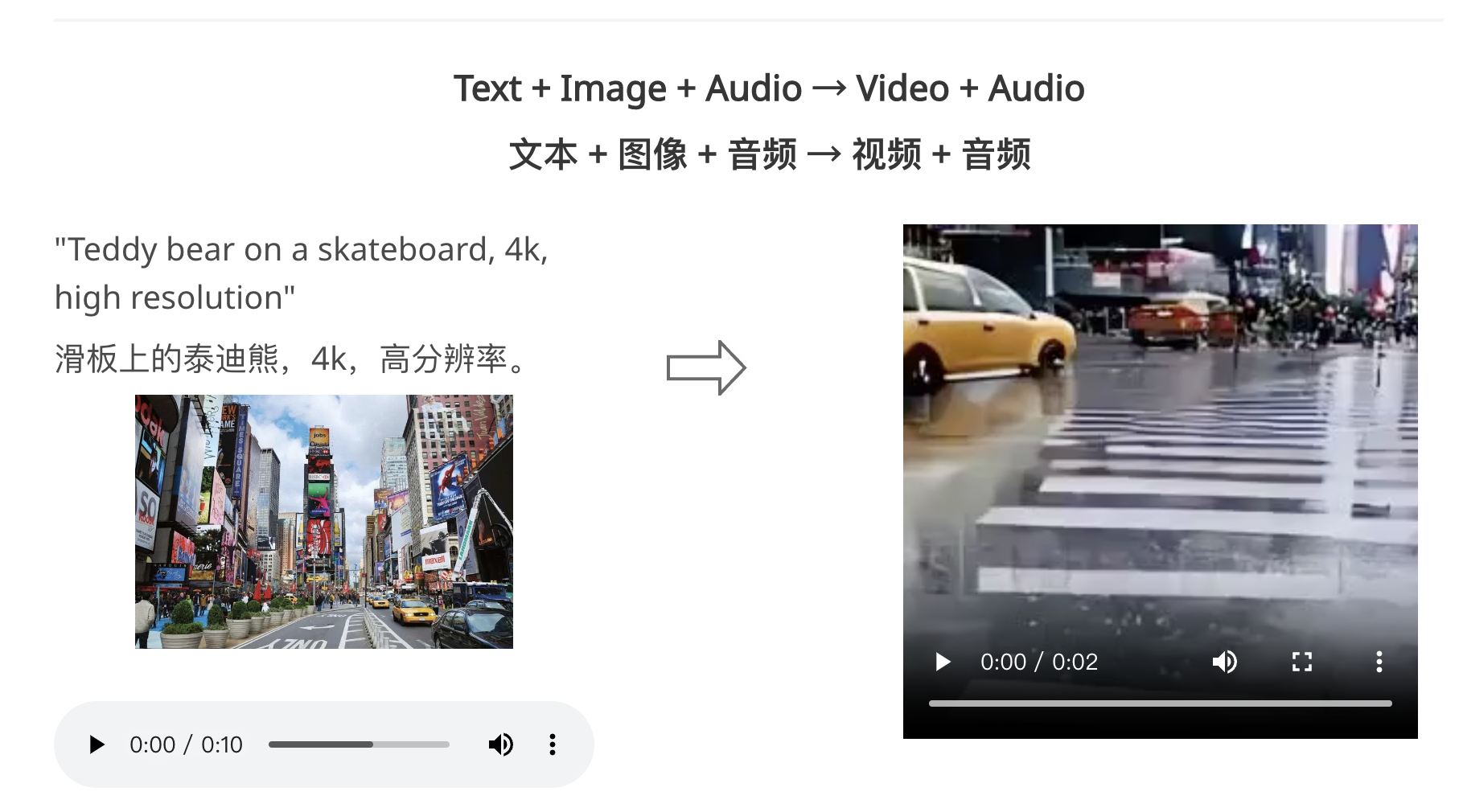
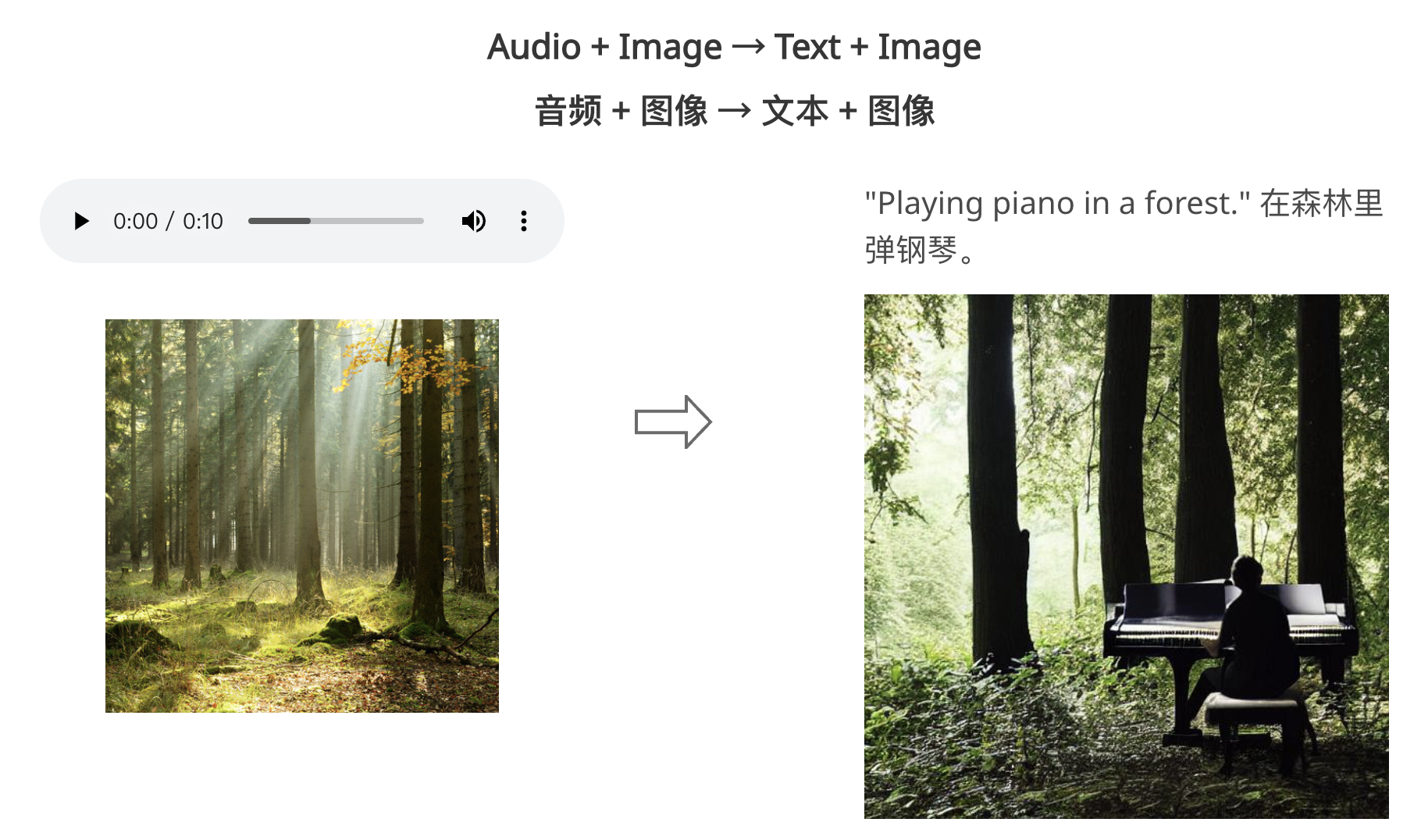

CoDi是一种多模态工具,可将各种混合模式(文本、图像、视频、音频)映射到其他任意混合模式。目前已有的GPT-4模型支持将(文本、图像)转化为文本,但预计未来会有更多模型在多模态输入/输出方面展现出更高的灵活性。
论文地址:
http://arxiv.org/abs/2305.11846
项目代码:
https://github.com/microsoft/i-Code/tree/main/i-Code-V3
演示地址:
https://codi-gen.github.io/
本文地址:https://www.163264.com/3564
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
