

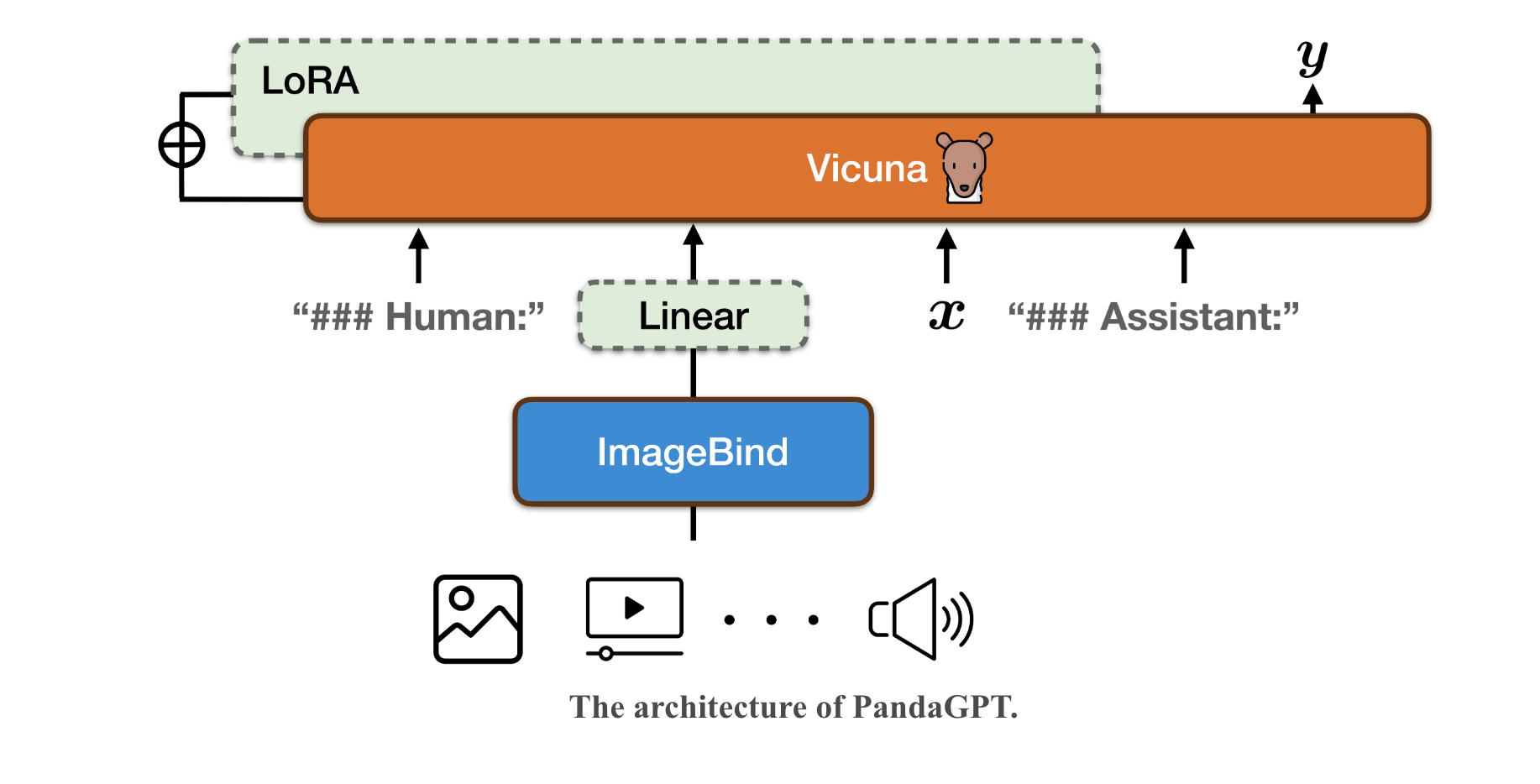
PandaGPT采用ImageBind编码输入数据,使用Vicuna跟踪语言指令。PandaGPT能够解锁数据在六个模态(图像/视频、音频、文本、深度、热图、IMU)中的各种新颖多模态能力,例如复杂的理解/推理、多轮对话等。
图片/视频接地问答。图像/视频启发的创意写作。视觉和听觉推理。多模态算法。


Project Page: panda-gpt.github.io
Demo: huggingface.co/spaces/GMFTBY/
Code: github.com/yxuansu/PandaG
本文地址:https://www.163264.com/3578
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 