


红杉美国发表了一篇新文章《The New Language Model Stack》。这篇文章分析了投资 Portfolio 里的 33 家小到种子轮,大到已经上市的公司,并总结出了八个关键点。每个点都结合了当前的最新趋势,并给出了对未来的预测。不仅值得一读,而且可以帮助读者更好地了解这个领域的最新进展。
原文地址:
https://www.sequoiacap.com/article/llm-stack-perspective/

65% 的公司已经将应用投入生产,94% 的公司正在使用基础模型 API,88% 的公司认为检索技术,38% 的公司对像 LangChain 这样的 LLM 编排和应用开发框架感兴趣,不到 10% 的公司正在寻找用于监控 LLM 输出、成本或性能并进行 A/B 测试提示的工具,少数公司正在研究补充性的生成技术,15% 的公司从头开始或使用开源资源构建了自定义的语言模型。
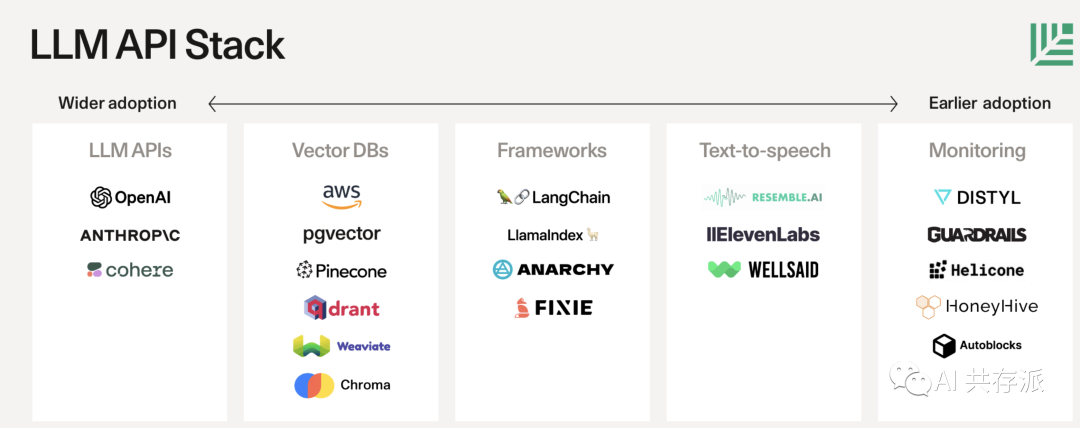
LLM API方面涉及的工具包括OpenAI, ANTHROPC, 以及Cohere等;向量数据库(Vector DBs)方面包括AWS, pgvector, 以及Pinecone等;开发框架方面包括LangChain, Llamalndex, 以及ANArCHY等;文本到语音(Text-to-speech)技术方面有Resemble.AI, ElevenLabs, 以及Wellsaid等;监控方面则包括Distyl, Guardrails, 以及Helicone等。
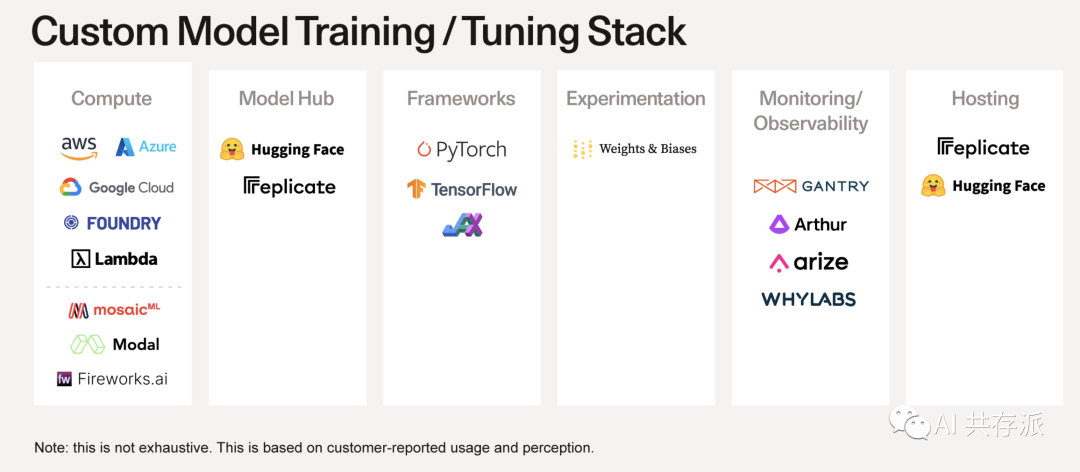
在自定义模型训练/调整技术栈中,有许多有用的工具。这些工具可以帮助你计算、管理模型、开发框架、进行实验、监控、以及托管模型。其中,计算方面的工具包括aws、Google Cloud和Lambda等。模型中心方面则有Azure和Feplicate等。开发框架方面则包括Hugging Face、TensorFlow等。实验方面则有Weights & Biases、GANTRY和FOUNDARY等。监控/可观察性方面包括Feplicate、Arthur和arize等。最后,托管方面则包括WHYLABS和Mosaic”Modal等。
AI总结篇:
1. 几乎所有 Sequoia 网络中的公司都在将语言模型应用于其产品中,如代码、数据科学、聊天机器人、销售、法律、会计、搜索、消费支付和旅游规划等领域。
2. 新的语言模型 API、检索和编排构成了这些应用程序的新堆栈,开源使用也在增长。94%的公司正在使用基础模型 API,OpenAI 的 GPT 是样本中明显的首选,但 Anthropic 的兴趣在过去的季度中有所增长。88%的公司认为,检索机制(如向量数据库)将仍然是其堆栈的关键部分。
3. 公司希望将语言模型定制为其独特的上下文。目前,有三种主要的方式来自定义语言模型:从头开始训练自定义模型、对基础模型进行微调和使用预训练模型并检索相关上下文。
4. 今天,LLM API 的堆栈与自定义模型训练堆栈感觉上是分开的,但随着时间的推移,这些堆栈将越来越融合。
5. 语言模型 API 正变得越来越适合开发人员使用,这将导致更多的面向开发人员的工具。
6. 语言模型需要变得更加可信(输出质量、数据隐私、安全性)才能得到全面采用。
7. 语言模型应用将变得越来越多模态化,多种生成模型将被结合使用。
8. AI 正开始渗透到技术的每一个角落,只有 65% 的受访者正在生产中,许多应用程序相对简单。基础架构层将在未来几年内继续快速发展。
来源:https://mp.weixin.qq.com/s/ifIhUQO39lIUyUzaJx3Hfg
本文地址:https://www.163264.com/4288
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
