


– 大型语言模型是构建软件的强大新原语。
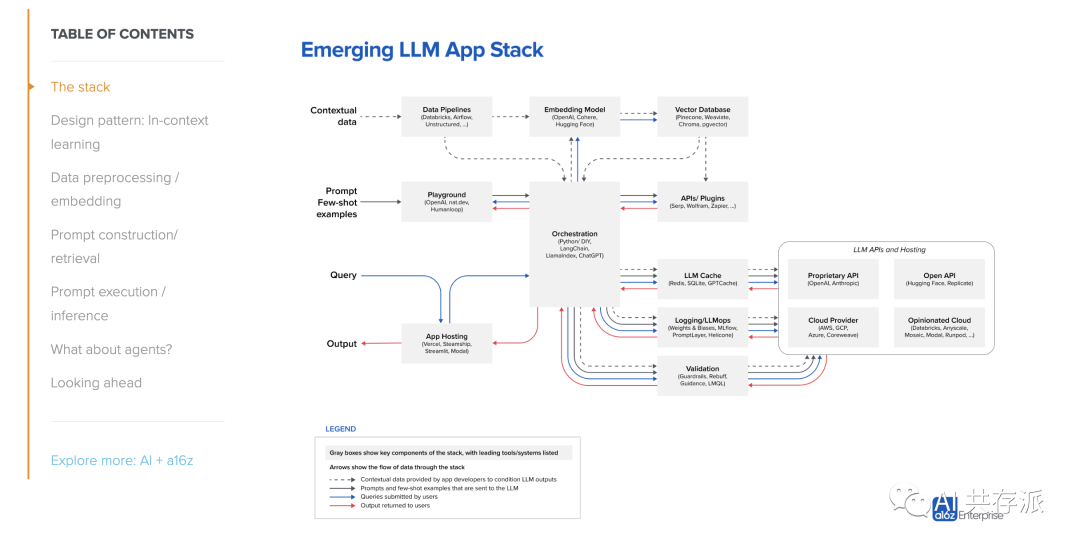
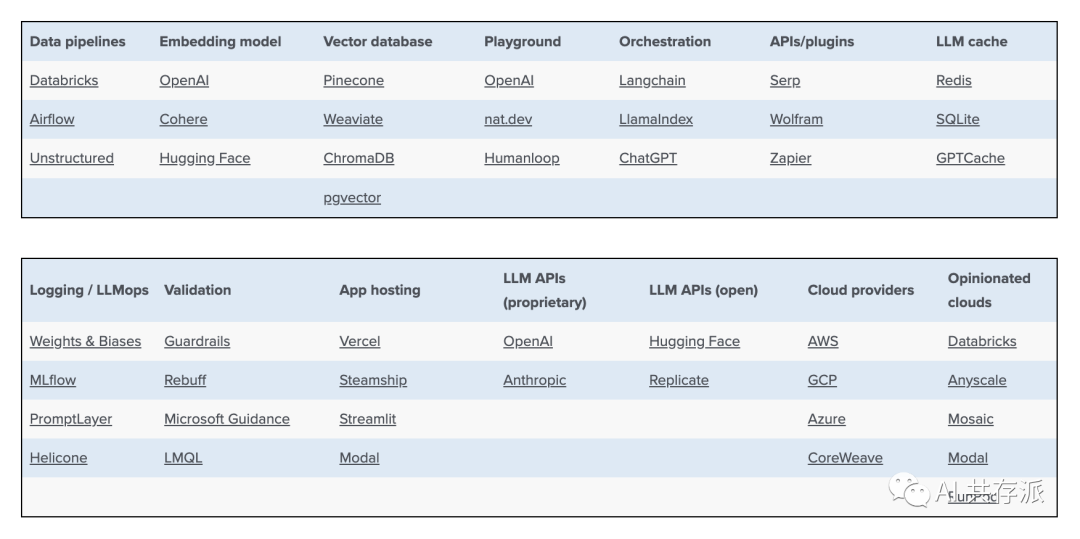
– LLM 应用程序堆栈是新兴的参考架构,展示了人工智能初创公司和尖端科技公司使用的常见系统、工具和设计模式。
– 堆栈还处于早期阶段,可能会随着底层技术的进步而变化。
– 该工作基于与人工智能初创公司创始人和工程师的对话。
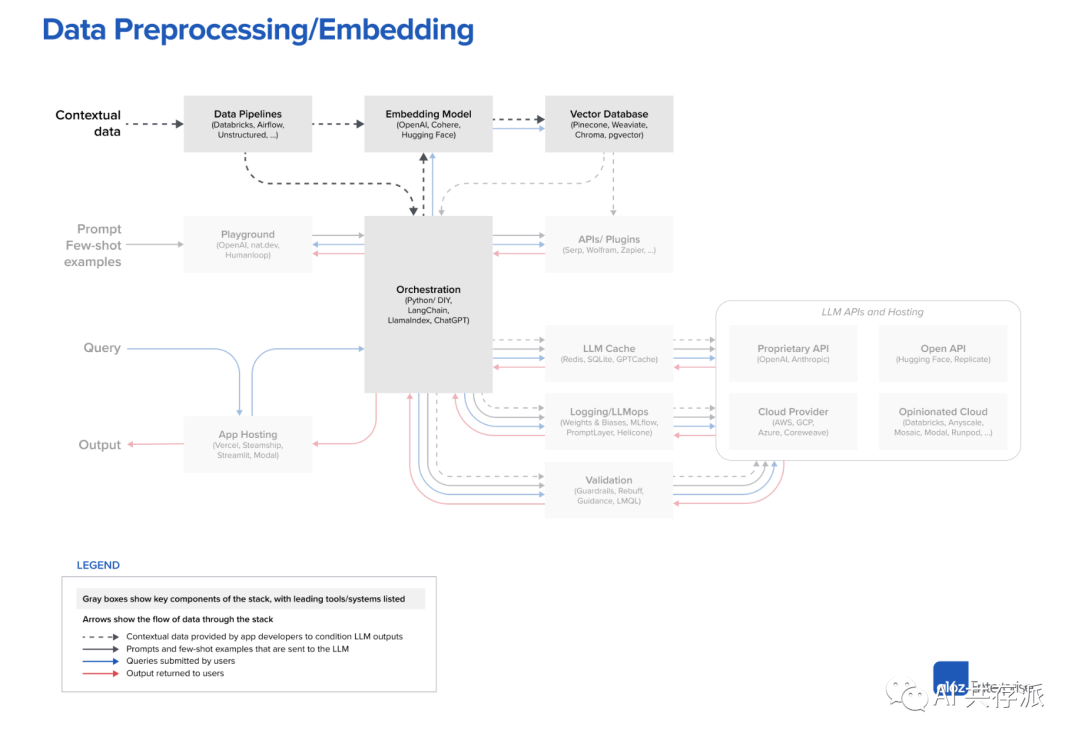
– 设计模式:情境学习是一种常见的方法,使用现成的法学硕士并通过对私人数据的调节来控制其行为。
– 情境学习通过只发送最相关的文档来解决输入文本限制的问题。
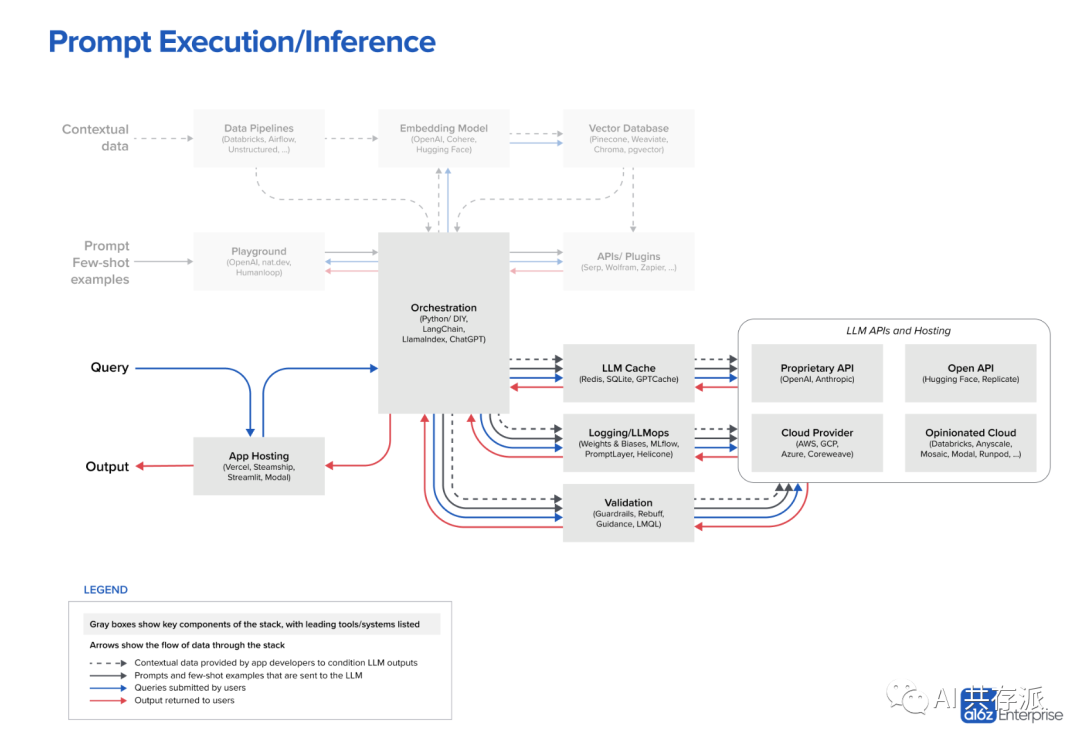
– 工作流程可以分为数据预处理/嵌入、提示构造/检索和回答查询三个阶段。
– 可以在不写一行代码的情况下对LLM进行微调
– 这是开源LLM领域的一项突破,可以将人工智能的开发和应用速度提高一个数量级
– LLM在出厂时了解很多事情,但专业知识有限
– 可以通过微调模型来教给它专业知识
– 微调模型可以使得使用LLM的效果更好
– 很多公司使用开源模型,如LLaMA和Falcon,以获得更多对数据、费用和模型响应的控制
– 但是微调模型既不简单也不便宜,需要大量时间和GPU计算,并且很难找到有经验的人来操作
– @monstersapi团队发布了一种无需编写任何代码即可微调LLM的能力
– 可以使用多个模型进行微调
– 使用他们的无代码工具不仅可以避免处理代码、复杂性和硬件的问题,还可以以更低的成本进行微调
– 他们的秘密是使用了分散的GPU平台,使得过程更具成本效益
– 他们提供了一个简单的逐步演示,展示了这个过程有多简单
– 可以使用代码SANTIAGO免费获得5000个积分来尝试他们的平台

原文地址:
https://a16z.com/2023/06/20/emerging-architectures-for-llm-applications/
来源:https://mp.weixin.qq.com/s/bEKEQiy3uSO-iZSvj7G2Kw
本文地址:https://www.163264.com/4524
 微信扫一扫,鼓励一下~
微信扫一扫,鼓励一下~ 
