模型框架
-
Ferret-UI:苹果开发出能“看懂”手机屏幕上并能执行任务的多模态模型
根据提供的PDF文档内容,以下是对”Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs”论文的归纳总结: 1. **研究背景**:– 移动应用程序已成为日常生活中的重要组成部分,但现有的多模态大型语言模型(MLLMs)在理解和与用户界面(UI)屏幕有效交互方面存在不…
-
MagicTime:可以生成延时视频的模型

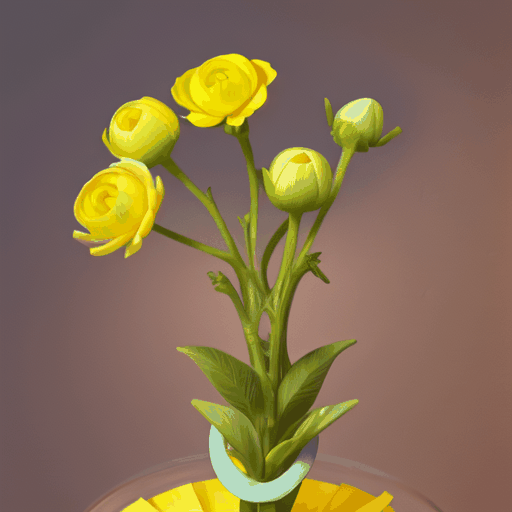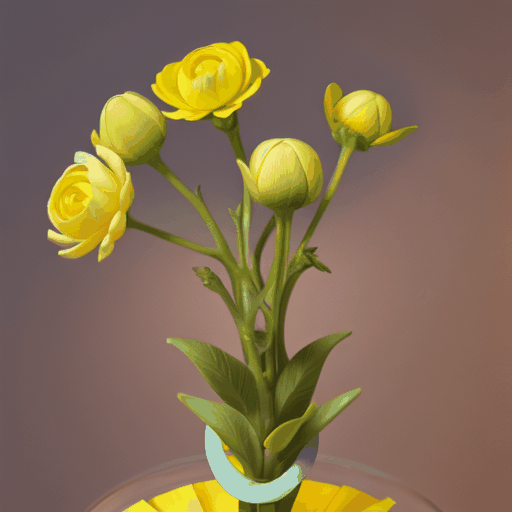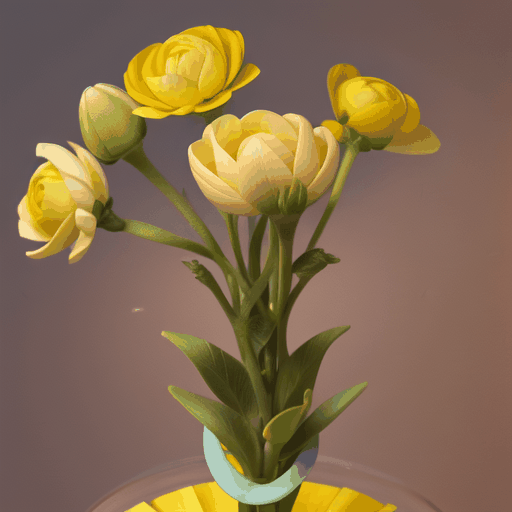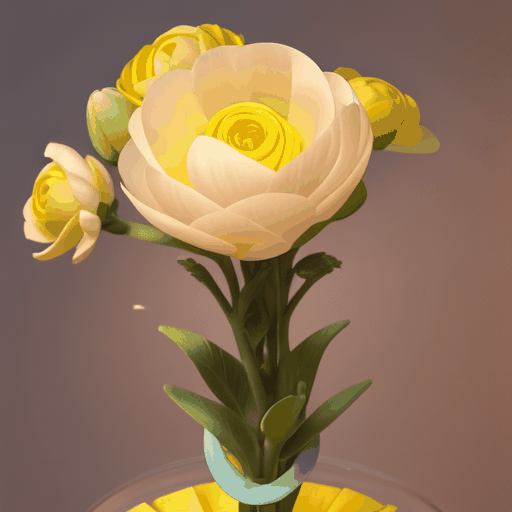


1. **项目背景**:– MagicTime是由北京大学、罗切斯特大学、新加坡国立大学、广东工业大学和加州大学圣克鲁斯分校共同研发的项目。– 该项目旨在生成高质量的变化时延视频(metamorphic videos),这些视频能够展示物体随时间变化的过程。 2. **研究问题**:– 现有的文本到视频生成(Text-to-Video, T2…
-
Mistral AI 开源了 Mistral 8X22B 模型,发布磁力链(262 GB)
地址: magnet:?xt=urn:btih:9238b09245d0d8cd915be09927769d5f7584c1c9&dn=mixtral-8x22b&tr=udp%3A%2F%http://2Fopen.demonii.com%3A1337%2Fannounce&tr=http%3A%2F%http://2Ftracker.opentrac…
-
谷歌推出 Gemini 1.5 Pro 公共预览版 ,支持处理音频
根据提供的网页内容,以下是对谷歌Gemini 1.5 Pro模型免费开放的归纳总结: 1. **对外开放**:谷歌的最强大模型Gemini 1.5 Pro已经全面对外开放,目前完全免费供开发者和普通用户使用。 2. **使用方式**:开发者可以通过API调用的方式使用Gemini 1.5 Pro,而普通用户可以直接在谷歌AI Studio中体验该模型。 3. **音频理解功能*…

-
OpenAI 向开发人员提供具有视觉能力 GPT-4 Turbo with Vision
根据提供的网页内容,以下是对OpenAI发布GPT-4-Turbo正式版的归纳总结: 1. **产品发布**:OpenAI发布了GPT-4-Turbo的正式版,这是一个经过改进的人工智能模型,之前一直以预览版的形式提供给用户。 2. **模型访问**:用户可以通过“gpt-4-turbo”这一名称来访问和使用这个模型,其最新版本为“gpt-4-turbo-2024-04-09”…
-
用于3D重建和生成的大型高斯重建模型GRM:少量图片能在短时间内构建出物体的3D模型或整个场景
该内容介绍了一种名为GRM的大规模重建器,能够从稀疏视图图像中恢复3D模型。GRM是一种基于Transformer的前馈模型,能够有效地将输入像素转化为像素对齐的高斯函数,从而创建一组表示场景的密集分布的3D高斯函数。该方法在重建质量和效率方面表现出优势,并展示了在生成任务中的潜力。该项目得到了Google、三星和瑞士博士后流动奖学金的支持。 项目地址: https://jus…
-
苹果研究人员开发了一种新的AI系统ReALM,模型性能优于GPT-4
近日,苹果研究人员开发了一种新的AI系统ReALM,该系统可以理解屏幕上实体、对话和背景上下文的模糊引用,从而实现与语音助手的更自然的交互。ReALM的一项关键创新是使用解析的屏幕上实体及其位置来重建屏幕,以生成捕获视觉布局的文本内容。研究人员证明,这种方法与专门用于参考解析的微调语言模型相结合,可以在该任务上优于GPT-4。苹果研究人员在论文中写道:“让用户能够对屏幕上看到的…
-
AI芯片创企Groq推出了Mixtral 8x7B API,采用自研AI芯片 推理速度超英伟达GPU十倍
近日,AI芯片创企Groq推出了Mixtral 8x7B API,据AI模型和托管提供商ArtificialAnalysis.ai的测评数据,该接口创下了新的大模型吞吐量记录,达到每秒430 Tokens。Groq还提供Llama2 7B模型访问,最高可实现每秒750 Tokens。据介绍,Groq平台基于其自研LPU(语言处理单元)芯片运行,该芯片在大模型推理任务上速度是英伟…
-
OpenAI推出文本到视频生成器Sora,根据文字描述创建长达60秒的视频,非常适合重现梦境
如果你以为OpenAI Sora只是像DALLE那样的创意玩意儿,那你就需要重新思考了。Sora是一个数据驱动的物理引擎,它能模拟各种世界,无论是现实的还是虚构的。这个模拟器通过去噪技术和梯度计算来学习复杂的渲染、直观物理、长期推理和语义基础。 如果说Sora使用了虚幻引擎5来训练大量合成数据,我一点也不会感到意外。它肯定是这样的! 让我们来分析一下下面的视频。提示:“两艘海盗…








